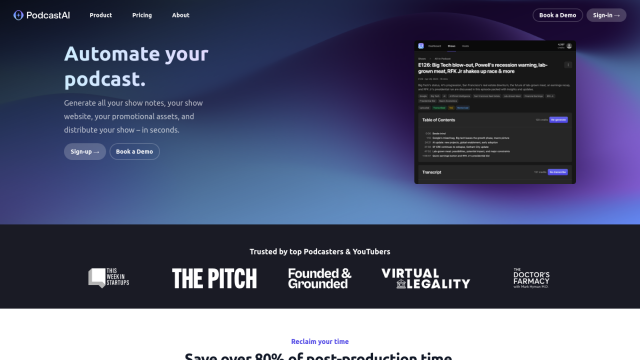
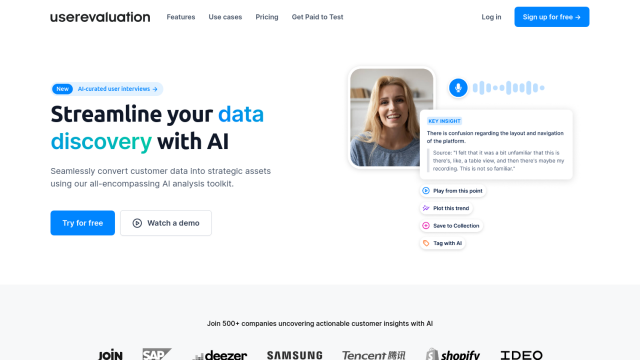
Question: I'm looking for a platform that can extract valuable insights from unstructured audio data, including timestamps and topic classification.
Gladia
For extracting insights from unstructured audio data, including timestamps and topic classification, Gladia offers a robust AI transcription API. The platform uses Whisper ASR technology to offer high accuracy transcription, speaker diarization, code-switching, and multilingual speech-to-text translation in 99 languages. Gladia also offers summarization and topic classification, making it a good fit for content and media, virtual meetings, workspace collaboration, and call centers. Pricing begins with a free tier and extends to Pro and Enterprise plans for heavy use.

AssemblyAI
Another option is AssemblyAI, which offers a variety of AI models for speech-to-text transcription, speaker detection, sentiment analysis, chapter detection, and PII redaction. Trained on 12.5 million hours of multilingual audio data, the platform supports more than 99 languages and offers flexible integration tools with a free tier and pay-as-you-go pricing. AssemblyAI is geared for companies building new AI products that use voice data and offers data security with compliance to GDPR, PCI-DSS, and SOC 2 standards.

Wordcab
Wordcab is another AI suite that processes and analyzes large amounts of unstructured communications. It offers multilingual transcription in 57 languages, downstream conversation intelligence, data inquiry, and easy-to-use analytics. Wordcab is good for sales, support, legal, and medical use cases, and it prioritizes data security with SOC 2 Type 2 certification and GDPR compliance.

Deepgram
For a platform that also offers text-to-speech capabilities, Deepgram offers high accuracy speech-to-text and audio intelligence features. Deepgram's speech-to-text API supports multiple languages and is good for speech analytics and media transcription, while its text-to-speech API uses human-like voice models for low-latency voicebots. Deepgram offers detailed documentation and a free $200 credit to get started, making it a relatively affordable option.