Embedditor Alternatives

Trieve
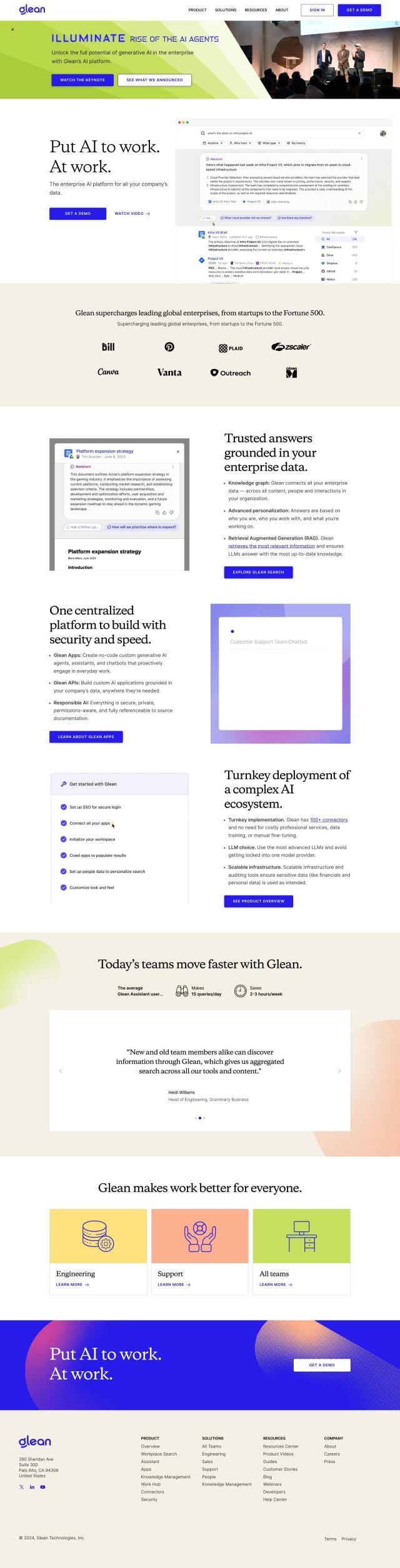
If you're looking for a replacement for Embedditor, Trieve is worth a look. Trieve is a full-stack infrastructure designed for building search, recommendations, and Retrieval-Augmented Generation (RAG) experiences. It supports private managed embedding models, semantic vector search, and hybrid search, making it well-suited for more advanced use cases. With a free plan that supports up to 10,000 vectors for non-commercial self-hosting, Trieve is easy to get started and has a variety of paid plans to accommodate different needs and scale.


Pinecone
Another contender is Pinecone. Pinecone is a vector database geared for fast querying and retrieval of similar matches. It offers low-latency vector search, metadata filtering, and hybrid search, which can be a big boost in efficiency. Pinecone also supports real-time updates and integrates with big cloud providers, so it's a good choice for enterprise use. It has a variety of pricing tiers, including a free starter plan, so you can pick what works best.


Neum AI
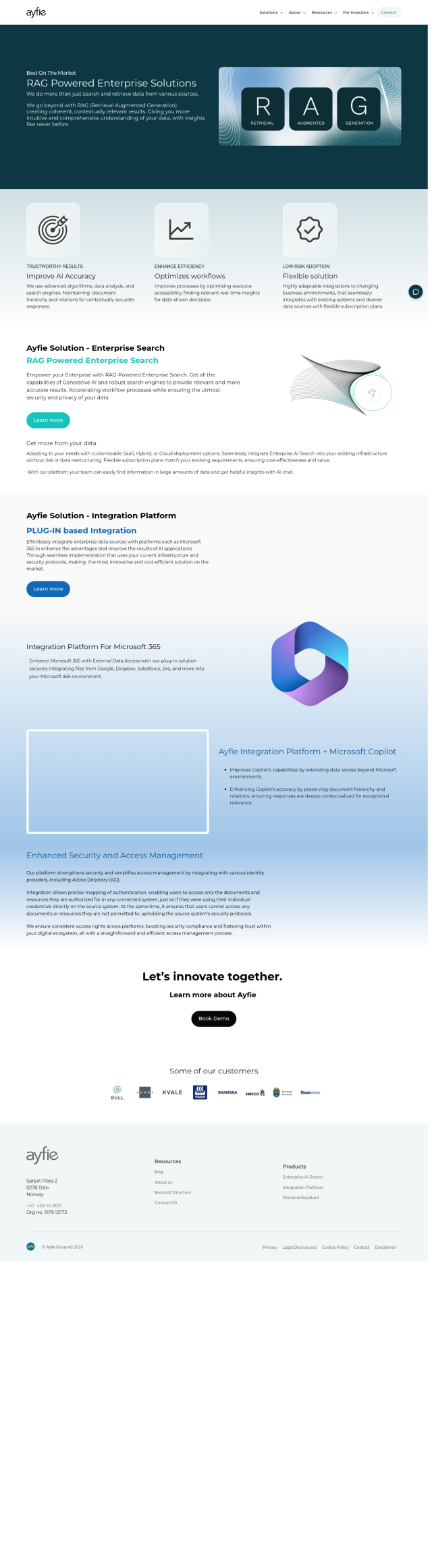
If you want a framework for building and managing your own data infrastructure, Neum AI is worth a look. It has connectors to convert unstructured and structured data into vector embeddings and supports scalable pipelines to process millions of vectors. Neum AI also offers real-time data embedding and indexing, so it's good for big-scale and real-time data use cases. It has a variety of pricing tiers, including a free starter plan, so you can pick what works best.