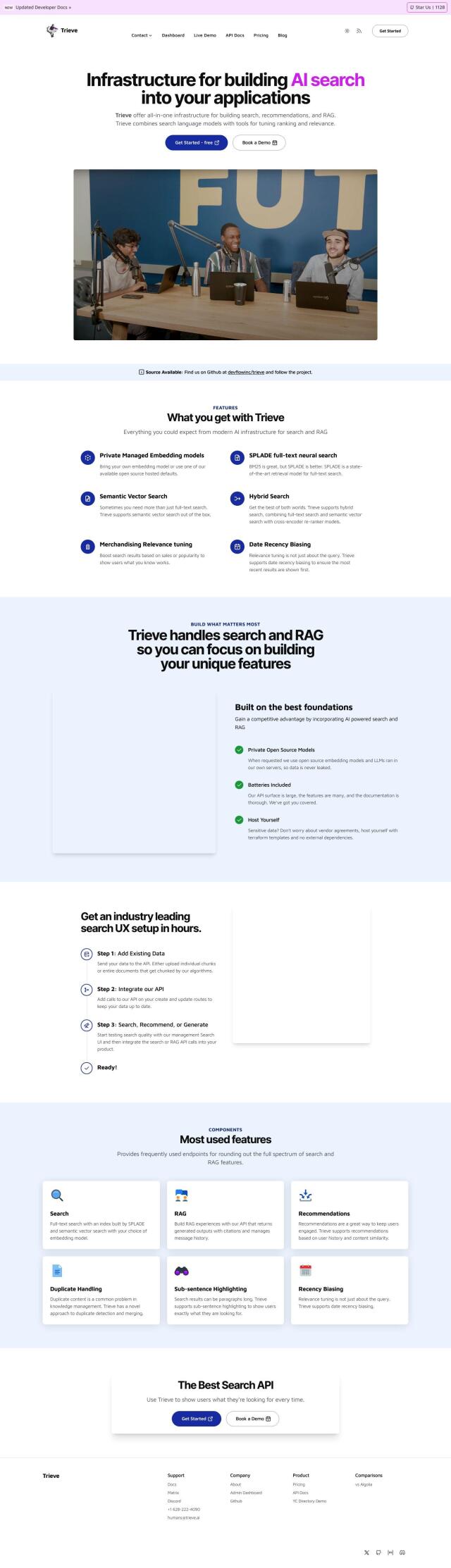
Embedditor is an open-source tool that optimizes embedding metadata and tokens for vector search. It offers a simple interface to apply advanced NLP techniques like TF-IDF and normalization to increase efficiency and accuracy in Large Language Model (LLM) related applications.
Some of its key features include:
- Improved Embedding Tokens: Apply advanced cleaning techniques to remove noise and irrelevant tokens, such as stop-words and punctuation, to increase search relevance.
- Flexible Tokenization: Split or merge content based on its structure, adding void or hidden tokens to create more semantically meaningful chunks.
- Local and Enterprise Deployments: Run Embedditor on your local machine, in your own enterprise cloud, or on-premises for complete control over your data.
- Cost Savings: Remove low-relevance tokens to reduce embedding and vector storage costs by up to 40% while improving search results.
Embedditor is geared for users who want to take their vector search to the next level by optimizing embedding metadata and tokens. Some of the best use cases include optimizing LLM-related applications, improving the relevance of content in vector databases, and improving data security and cost efficiency.
Published on June 13, 2024
Related Questions
I'm looking for a tool to optimize my vector search by improving the quality of embedding metadata and tokens. How can I reduce the cost of storing and processing large language model data while maintaining search accuracy? Is there an open-source solution that can help me apply advanced NLP techniques to my content for better search results? Can you recommend a tool that helps me improve the relevance of content in my vector database by removing noise and irrelevant tokens?
Tool Suggestions
Analyzing Embedditor...