Question: Can you recommend a tool that helps me improve the relevance of content in my vector database by removing noise and irrelevant tokens?

Embedditor
If you want a tool to make your content in a vector database more relevant by scrubbing out noise and unimportant tokens, Embedditor is a good option. This open-source tool optimizes embedding metadata and tokens with more-advanced NLP processing like TF-IDF and normalization. It has a simple interface for fine-tuning embedding tokens, cuts storage costs by up to 40%, and improves search relevance, so it's a good choice for making your vector database content more relevant and your data more secure and efficient.
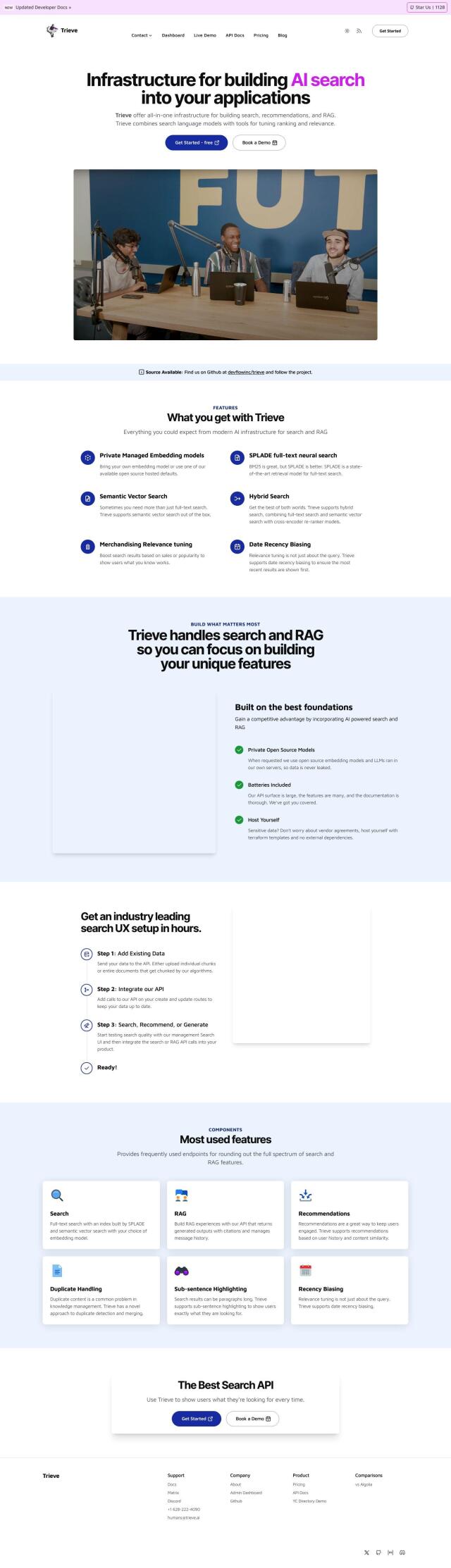
Trieve
Another powerful option is Trieve, which offers a full-stack foundation for building search, recommendations and Retrieval-Augmented Generation (RAG) experiences. Trieve supports private managed embedding models, SPLADE full-text neural search and semantic vector search. It also offers merchandising relevance tuning and multiple deployment options, including self-hosted and cloud-based services, so it's a good all-purpose tool for making your vector database more relevant.


Neum AI
If you want a more general-purpose data management system, check out Neum AI. This open-source framework is designed to build and manage data infrastructure for RAG and semantic search. It includes scalable pipelines to process massive amounts of vectors and keep them up to date in real-time. Neum AI supports real-time data embedding and indexing, so it's good for big data and real-time use cases.


Baseplate
Finally, Baseplate is a data management system that combines different types of data into a single hybrid database, and it's good for efficient embedding and storage. It has automatic versioning and multimodal LLM responses, which can help automate your data management and retrieval processes for high-performance AI use cases.