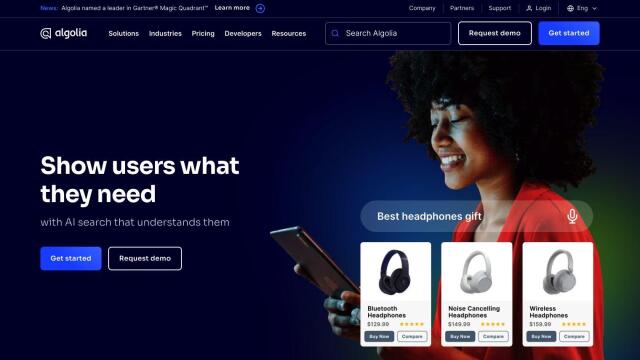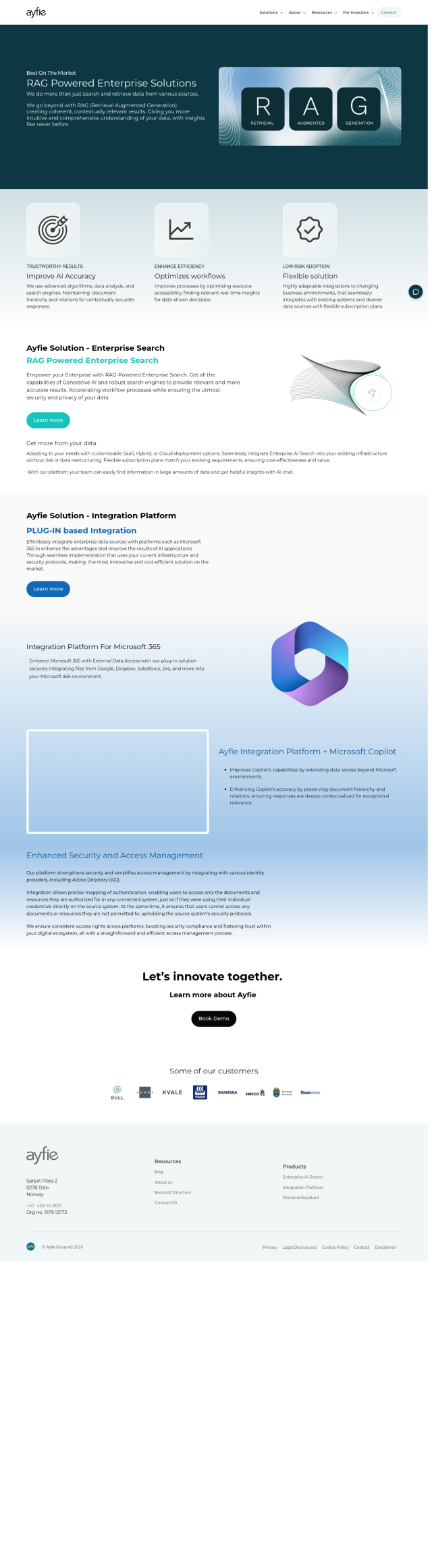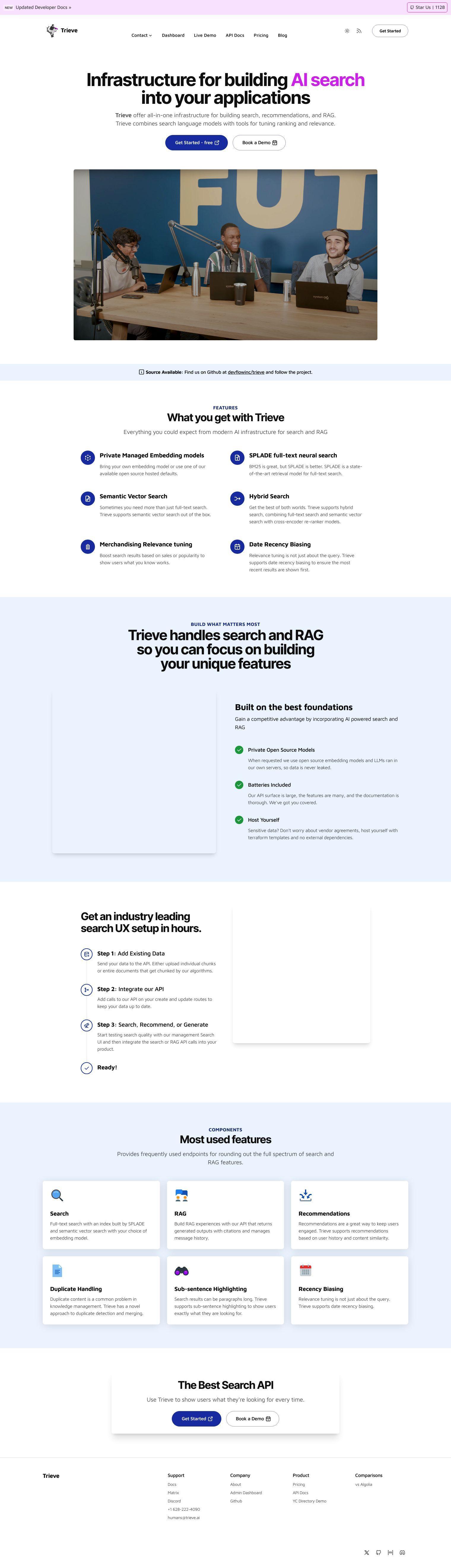
Trieve provides a single infrastructure for building search, recommendations and RAG (Retrieval-Augmented Generation) experiences. By combining language models with ranking and relevance fine-tuning tools, Trieve lets you deliver exactly what users want. Key features include private managed embedding models, SPLADE full-text neural search, semantic vector search and hybrid search.
Trieve is particularly useful for use cases that demand advanced search capabilities, such as date recency biasing, re-ranker models, semantic search, sub-sentence highlighting, document expansion, and more. You can either bring your own embedding model or use one of the open-source defaults. The platform also supports merchandising relevance tuning, so you can promote search results based on sales or popularity.
Trieve is designed to handle search and RAG, so you can focus on building custom features for your application. It's built on a strong foundation, combining AI-powered search and RAG to help you stand out. Trieve also provides private open-source models, which means you maintain control and data security. For maximum flexibility, users can run the service themselves using terraform templates and without any external dependencies.
Getting started is easy. You can import your existing data, integrate the API into your create and update routes, and begin testing search quality using the management Search UI. From there, you can integrate the search or RAG API calls into your product.
Trieve pricing is based on dataset size. The free plan is limited to 10,000 vectors/chunks for non-commercial self-hosting. Paid plans include:
- Dev Cloud: $25 per month, good for small teams and startups, with 100,000 vectorized and stored chunks, unlimited search queries and 2 datasets.
- Sovereign: $500+ per month (starting), for large organizations and agencies, with unlimited usage and the ability to run securely on your own servers or cloud.
- Pro Cloud: $500 per month, good for mid-sized datasets, with 1,000,000 vectorized and stored chunks, unlimited search queries and 10 datasets.
- Enterprise Cloud: $5000+ per month (starting), with contracted guarantees for organizations that need low latency and uptime, including a 99.9% uptime SLA and up to 175ms P95 hybrid search SLO.
All plans include 24/7 support and transparent pricing, so you can easily pick the right plan for your needs. Trieve is a great option for those who want to easily integrate advanced AI search capabilities into their applications, providing a comprehensive and customizable solution for building better search experiences.
Published on June 13, 2024
Related Questions
Tool Suggestions
Analyzing Trieve...