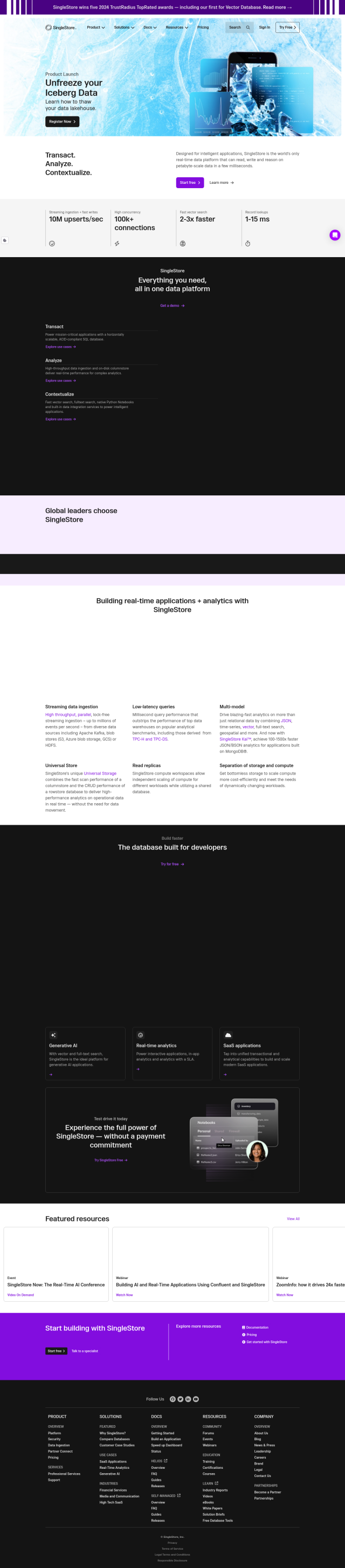
Question: How can I reduce the cost of storing and processing large language model data while maintaining search accuracy?

Exthalpy
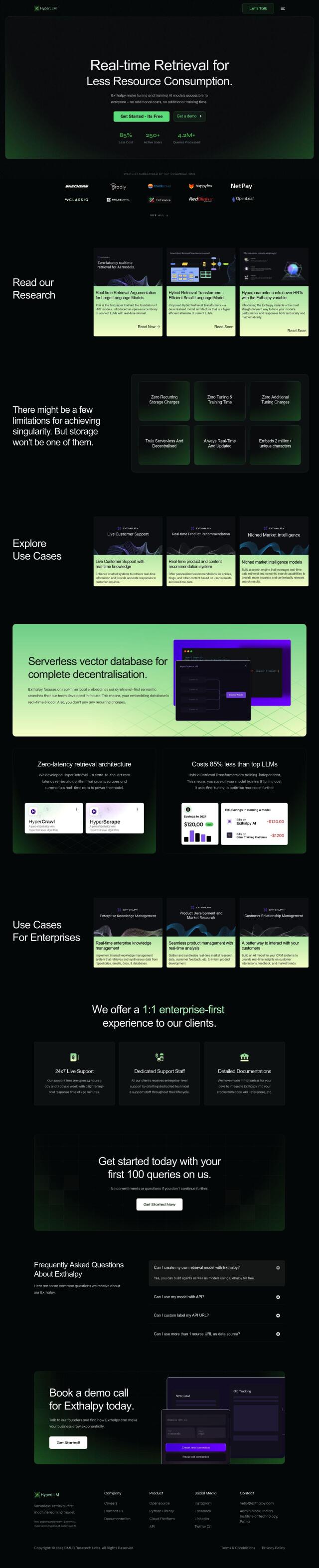
If you're looking for a way to cut the cost of large language model data storage and processing while still getting good search results, Exthalpy is another top pick. It's a serverless, decentralized design that means you don't have to pay for repeated storage and tuning. The platform is geared for real-time use cases like chatbots, personalized recommendations and market intelligence models. With live data access and real-time local embeddings, it can cut costs by up to 85% compared with large language models.


Predibase
Another top contender is Predibase, which offers a low-cost way to fine-tune and serve large language models. It offers free serverless inference for up to 1 million tokens per day and supports a broad range of models. Predibase's pay-as-you-go pricing and enterprise-grade security features make it a good choice for large-scale, high-performance use cases.


Pinecone
Pinecone is worth a look, too, especially if you need to be able to query and retrieve similar matches quickly. It's a serverless design that automatically scales without you having to worry about databases, which is good for low-latency vector search use cases. Pinecone's average query latency of 51ms and 96% recall are good for enterprise-class performance.

Embedditor
For optimizing embedding metadata and tokens, Embedditor is a useful open-source tool. It can improve efficiency and accuracy in large language model use cases by applying sophisticated NLP processing. The tool can filter out extraneous tokens and cut storage costs, too, which is good for anyone trying to wring more use out of LLM-related applications.