Question: I'm looking for an open-source framework to build and manage data infrastructure for Retrieval Augmented Generation and semantic search.


Neum AI
If you're looking for an open-source framework to build and manage data infrastructure for Retrieval Augmented Generation (RAG) and semantic search, Neum AI is a great choice. It provides a comprehensive set of tools to convert unstructured and structured data into vector embeddings, which can be used to create search indexes. The framework is designed for scalability and real-time data use cases, with built-in connectors for many data sources and models. It also supports real-time data embedding and indexing for RAG pipelines and integrates well with services like Supabase.
Trieve
Another excellent option is Trieve, which offers a full-stack infrastructure for building search, recommendations, and RAG experiences. It provides advanced search capabilities like SPLADE full-text neural search and semantic vector search, and allows customers to bring their own embedding models or use open-source defaults. Trieve supports private managed embedding models and provides various hosting options, including self-hosting with terraform templates.
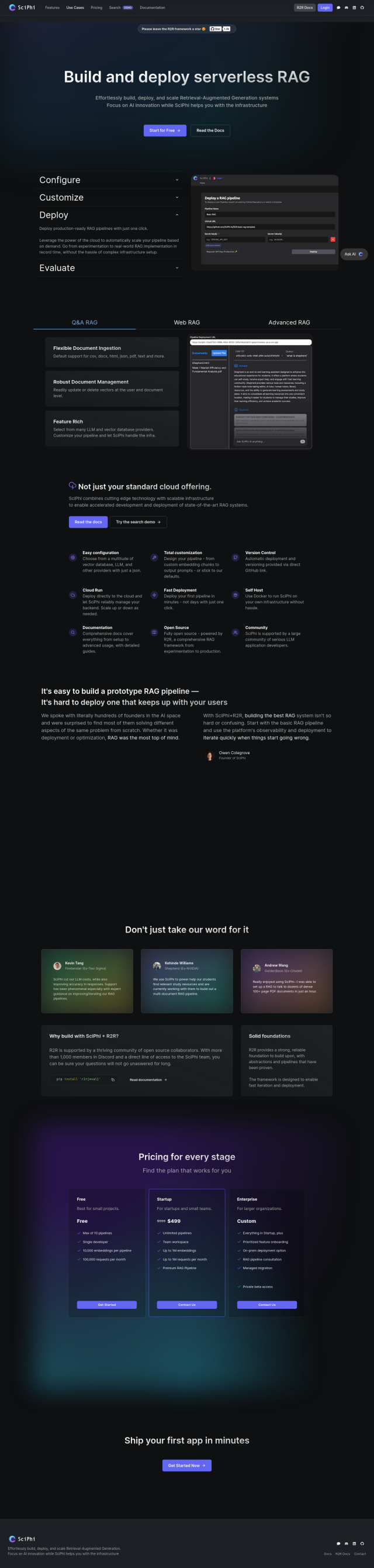
SciPhi
SciPhi is also a strong contender, particularly if you need a flexible system for managing the underlying infrastructure for RAG. It supports a variety of file formats, dynamic scaling, and deployment of state-of-the-art methods. SciPhi can be deployed to both cloud and on-prem infrastructure using Docker and offers different pricing tiers to suit various project sizes.


Pinecone
For a robust and scalable solution, Pinecone provides a vector database optimized for fast querying and retrieval of similar matches. It offers low-latency vector search, metadata filtering, and real-time updates, making it a good choice if you need to handle large amounts of data efficiently. Pinecone supports various data sources and models and provides extensive documentation and community support resources.