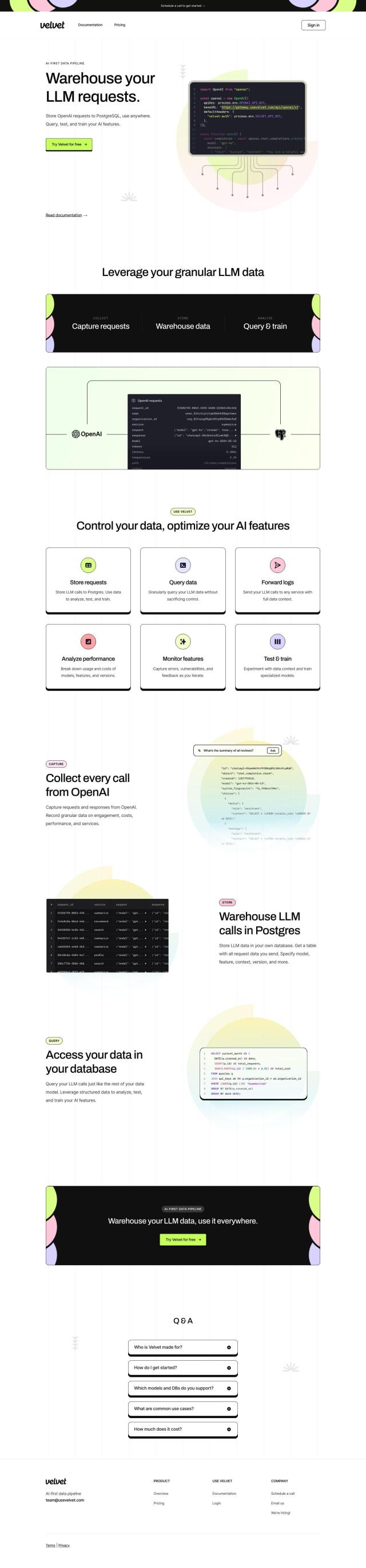
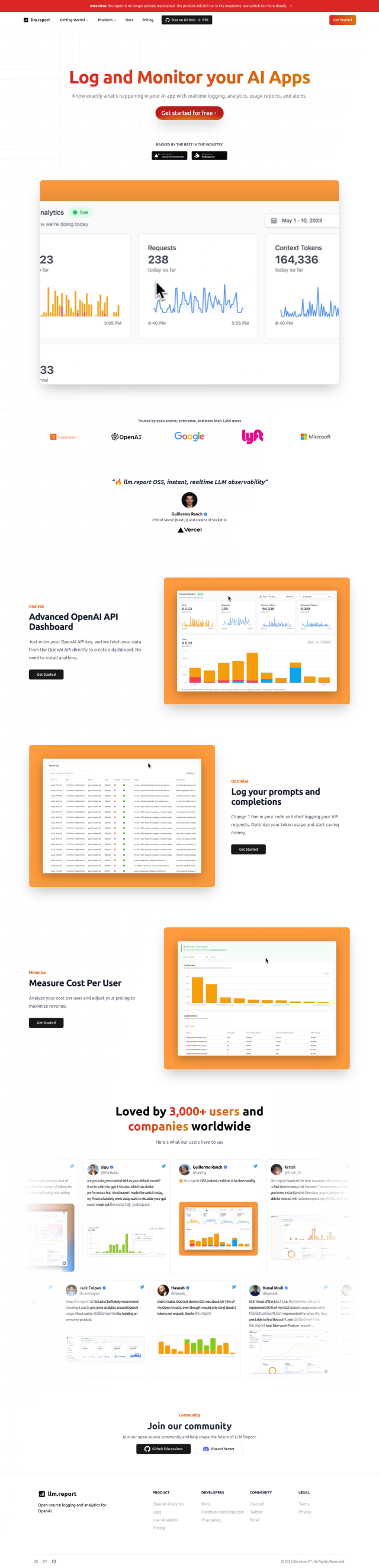
Question: Is there a solution that can help me monitor my LLM model's performance and detect any problems in real-time?

Langtail
If you need a more complete solution to monitor your LLM model's performance and catch any issues as they occur, Langtail is a great option. It provides a set of tools for debugging, testing, and deploying LLM prompts. With features like fine-tuning prompts, running tests, deploying as API endpoints, and monitoring performance with rich metrics, Langtail helps ensure your AI apps don't exhibit unexpected behavior and that your team collaborates more effectively. It also includes a no-code playground for writing and running prompts, so it's accessible to developers and non-technical team members.

Deepchecks
Another option is Deepchecks, which lets developers create LLM apps more quickly and with higher quality by automating evaluation and catching problems like hallucinations, bias and toxic content. It uses a "Golden Set" approach that combines automated annotation with manual overrides for a rich ground truth of LLM apps. Deepchecks' features include automated evaluation, LLM monitoring, debugging and version comparison, so it's good for ensuring reliable and high-quality LLM-based software from development to deployment.

LangWatch
If you want strong guardrails and real-time performance optimization, LangWatch is another option. It helps you avoid problems like jailbreaking and sensitive data leakage and offers continuous optimization through real-time metrics for conversion rates, output quality and user feedback. LangWatch also lets you create test datasets and run simulation experiments on custom builds, so you can ensure reliable and faithful AI responses.

Langfuse
Finally, Langfuse offers a broad set of features for debugging, analysis and iteration of LLM applications. It includes tracing, prompt management, evaluation and analytics, and support for integration with a variety of SDKs and frameworks. Langfuse's ability to capture full context of LLM executions and provide detailed metrics makes it a powerful tool for optimizing and maintaining your LLM models.