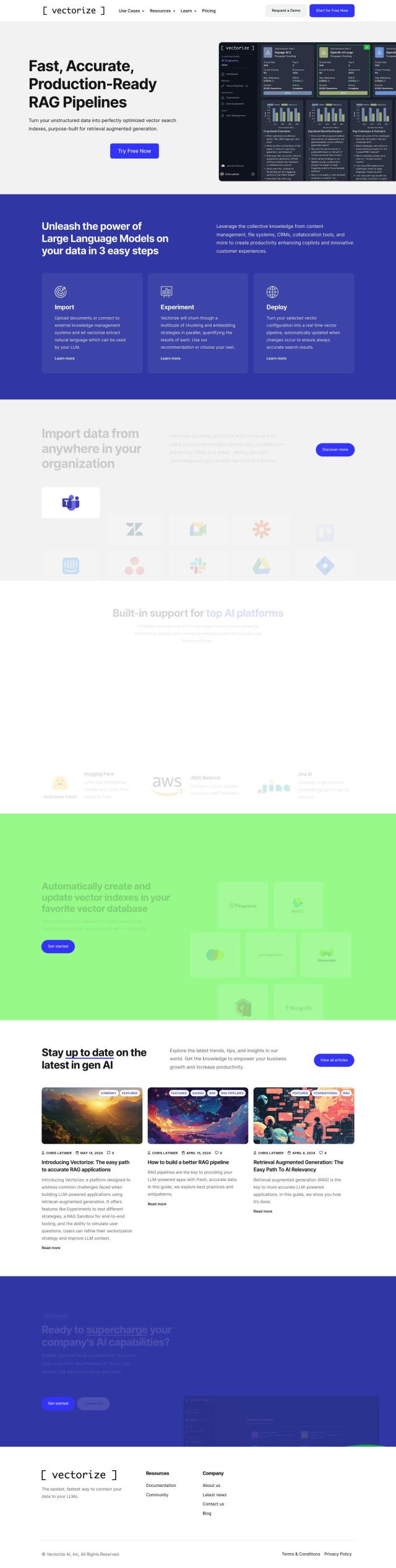
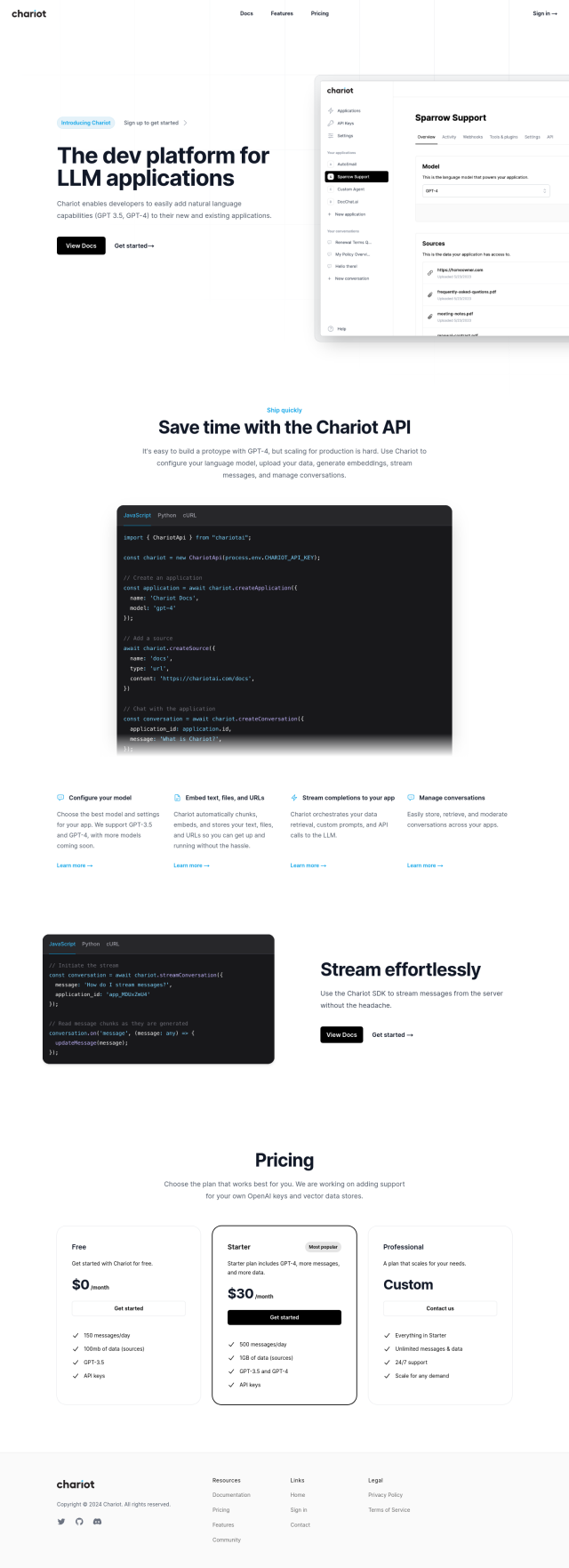
Question: Is there a library that provides a simple and extensible way to perform dependency parsing and word vector computation for natural language understanding?
spaCy
If you're looking for a full-fledged library for natural language processing, spaCy is a great option. It offers a variety of features like dependency parsing, word vector generation and support for more than 75 languages. With a lightweight API and support for plugging in your own models, spaCy is geared for performance and for handling large volumes of data. It also comes with tools like Prodigy for machine teaching and annotation, which makes it a good choice for large-scale information extraction tasks.


Neum AI
Another contender is Neum AI, an open-source framework for building and managing data infrastructure for Retrieval Augmented Generation (RAG) and semantic search. It offers scalable pipelines for processing millions of vectors and keeping them up to date. With connectors for different data sources and models, Neum AI can handle real-time data embedding and indexing, so it's good for large-scale and real-time use cases.
Lettria
If you're looking for a no-code AI platform, Lettria marries Large Language Models (LLMs) with symbolic AI for processing and extracting insights from text data. It includes tools for text preprocessing, mining and classification, and lets you create your own NLP models. It's good for turning unstructured text into reliable information and knowledge graphs, and for improving data security and privacy.

Qdrant
Last, Qdrant is an open-source vector database and search engine for fast and scalable vector similarity searches. It's designed for cloud-native architecture and is written in Rust for high-performance processing. Qdrant can be integrated with leading embeddings and frameworks. It offers cost-effective deployment options and flexible pricing models, making it good for a variety of use cases including advanced search and data analysis.