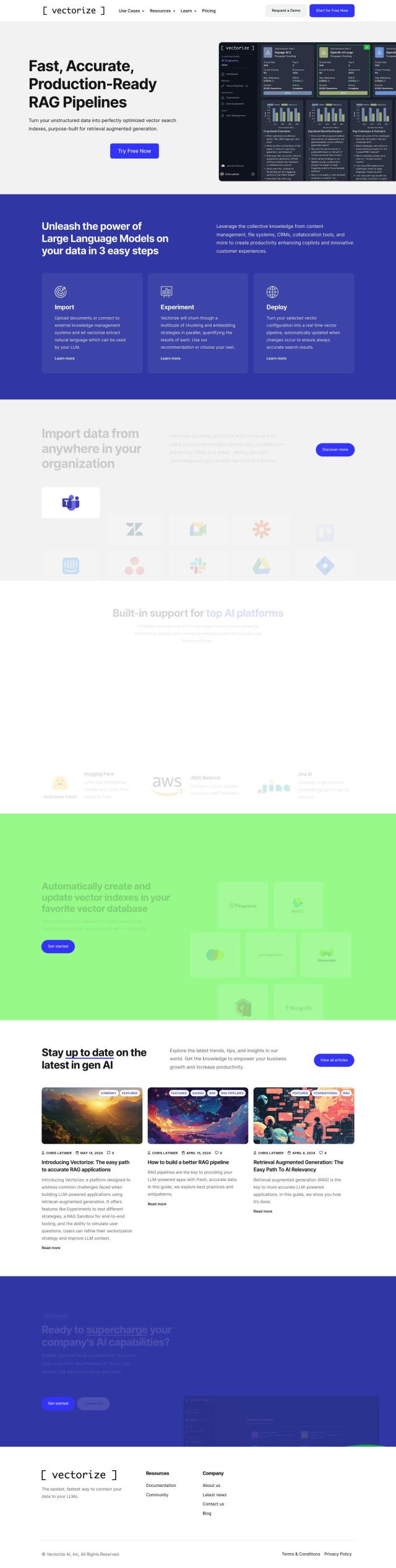
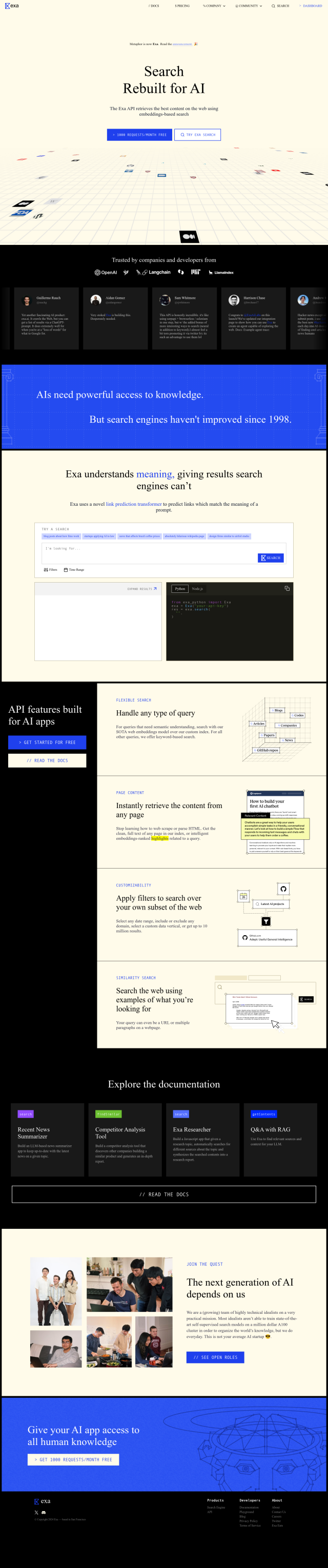
Question: Is there a platform that offers AI-powered embeddings and rerankers for advanced search capabilities?

Jina
For more advanced search, Jina offers a range of tools, including multimodal and bilingual embeddings, rerankers, LLM-readers, and prompt optimizers. Its reranker API can improve search relevance and RAG accuracy, supporting more than 100 languages and different data formats. Jina also offers auto fine-tuning for embeddings, which means you can build domain-specific models with relatively little training data. It can be deployed on-premises and offers a free trial.
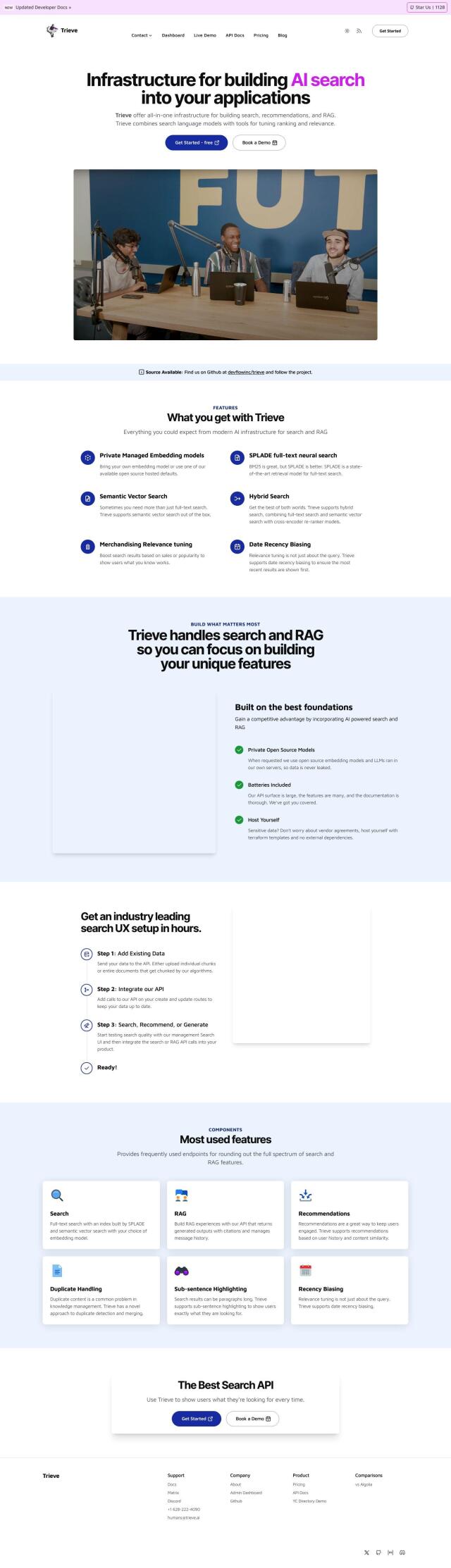
Trieve
Another strong contender is Trieve, which offers a full-stack foundation for building search, recommendations and RAG interfaces. It offers private managed embedding models, semantic vector search and full-text neural search, so it's well suited for more advanced use cases like semantic search and re-ranker models. Trieve also can use custom embedding models and offers flexible hosting with terraform templates.

Vespa
Vespa is a unified search engine and vector database that lets you perform fast vector search and filtering with machine-learned models. It can combine search across structured data, text and vectors in a single query, which makes it well suited for large-scale search applications. Vespa has auto-elastic data management and integrates with a variety of machine learning tools, so it's designed for high performance and low latency.

Qdrant
Qdrant is an open-source vector database and search engine for fast and scalable vector similarity searches. It's designed to scale cloud-natively and for high availability, and it integrates with popular embeddings and frameworks. Qdrant offers flexible deployment options, including a free tier, and has robust security features for enterprise use.