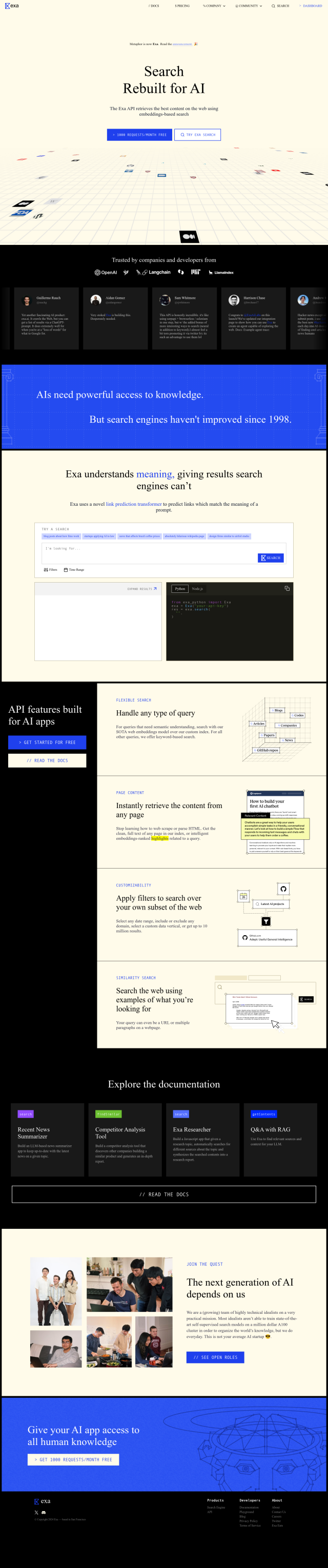
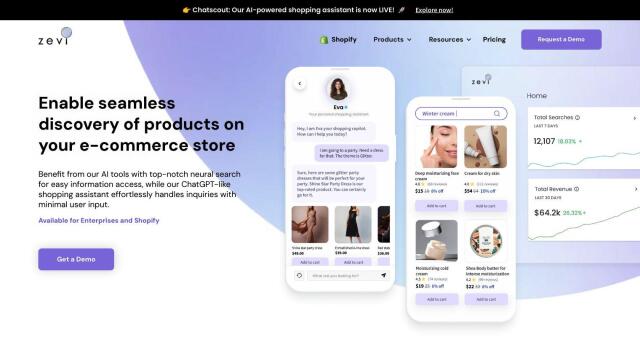
Vespa Alternatives

Trieve
If you're looking for another Vespa alternative, Trieve is worth a look. It's a full-stack infrastructure for building search, recommendations and RAG experiences that combines language models with ranking and relevance tools. Trieve supports private managed embedding models, semantic vector search and hybrid search, so it's well adapted to more advanced search use cases. It also offers a free plan for non-commercial self-hosting, and paid plans with different combinations of features and support.


Pinecone
Another good option is Pinecone, a serverless vector database designed to be fast for querying and retrieving similar matches. Pinecone supports low-latency vector search, real-time updates and hybrid search that combines vector search with keyword boosting. It's got a free starter plan and scalable standard and enterprise plans, so it's a good option for those who want to be frugal and secure for enterprise use.

Qdrant
Qdrant is an open-source vector database and search engine designed for fast and scalable vector similarity searches. It's got cloud-native scalability, easy deployment with Docker, and high-performance handling of high-dimensional vectors. Qdrant plays nice with other leading embeddings and frameworks, and pricing is flexible, including a free tier and cloud deployment options.

Algolia
Last is Algolia, an AI-powered search infrastructure that combines keyword search with vector understanding, dynamic re-ranking and personalization. It's got a broad range of industries and use cases, including enterprise search, headless commerce and voice search, and flexible pricing with a pay-as-you-go option and committed plans. That makes Algolia a good option for developers who want to build personalized search.