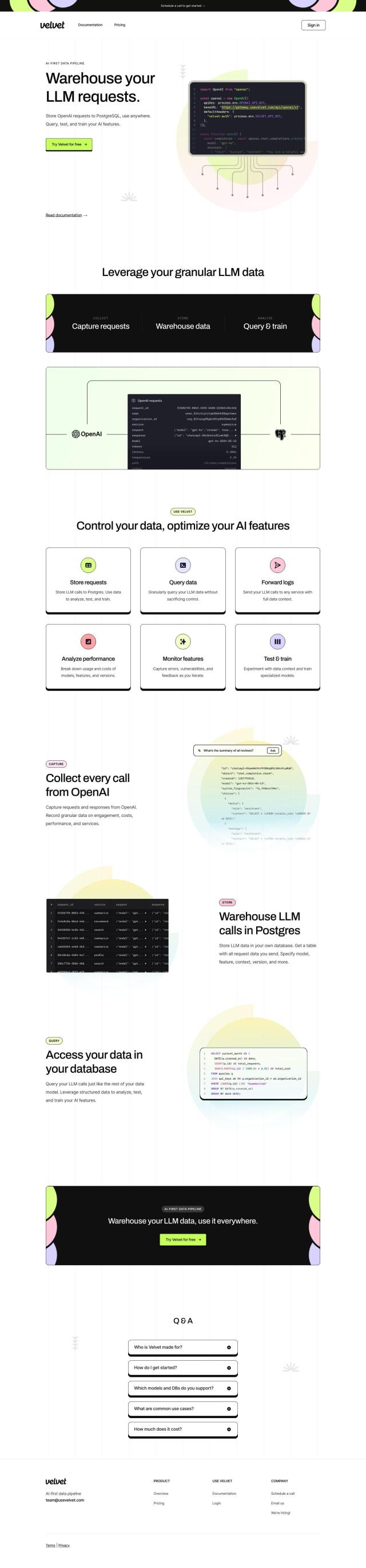
Question: Can you suggest a solution that can transform unstructured and structured data into vector embeddings for search indexes?


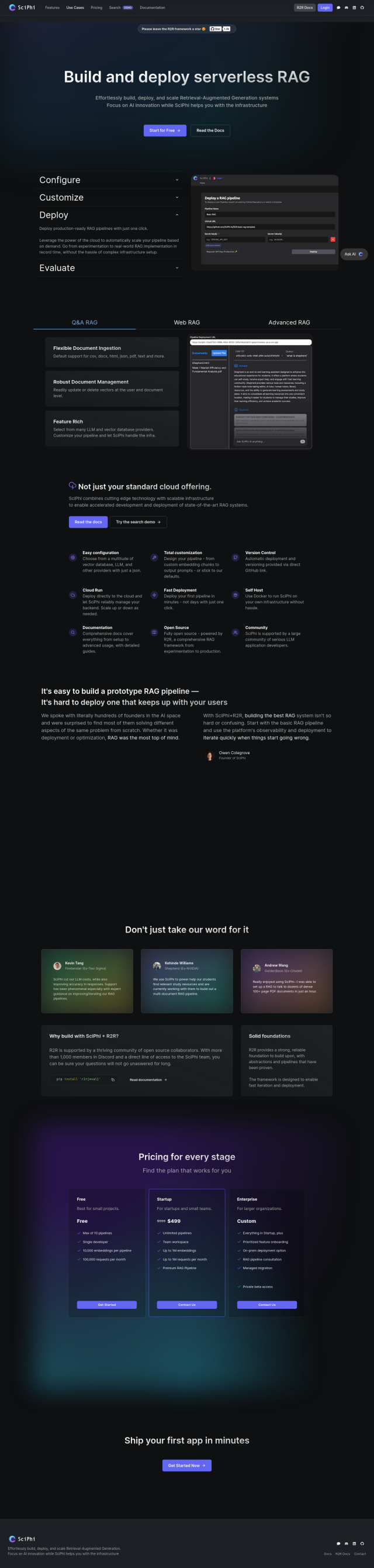
Neum AI
If you're looking for a way to convert both unstructured and structured data into vector embeddings for search indexes, Neum AI could be a good choice. This open-source framework is geared for building and managing data infrastructure for Retrieval Augmented Generation (RAG) and semantic search. It includes connectors to convert data into vector embeddings, scalable pipelines to process millions of vectors, and a production-ready cloud platform with real-time syncing and governance. Neum AI also integrates well with services like Supabase and has a variety of pricing options, including a free starter plan.
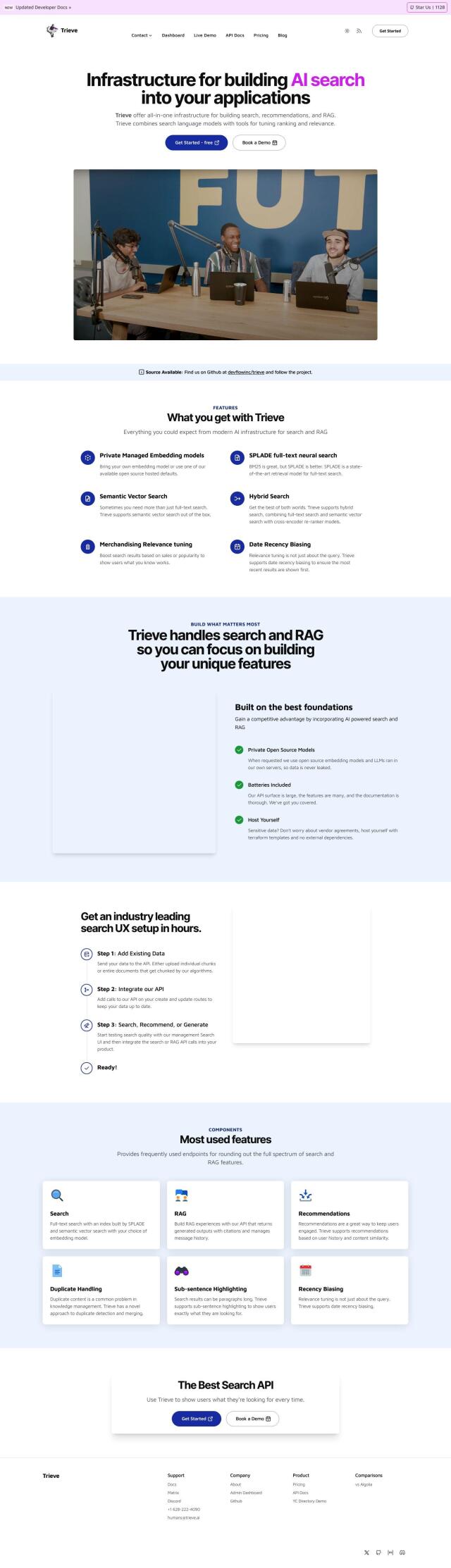
Trieve
Another good option is Trieve, a full-stack infrastructure for building search, recommendations and RAG experiences. It includes private managed embedding models, SPLADE full-text neural search and semantic vector search. Trieve offers advanced search features like date recency biasing and sub-sentence highlighting, and customers can use their own embedding models or defaults from open-source libraries. The service is easy to get started with, with a free plan for non-commercial self-hosting and several paid plans for different needs and scale.


Pinecone
If you prefer a more serverless approach, check out Pinecone. This vector database is designed for fast querying and retrieval of similar matches across billions of items in milliseconds. It offers low-latency vector search, metadata filtering and real-time updates, so it's good for high-scale use. Pinecone offers a range of pricing options and integrates with major cloud providers, so you can manage your data efficiently and securely.

Airbyte
Last, Airbyte is an open-source data integration platform that can move data efficiently from more than 300 structured and unstructured sources to many destinations. It includes a Connector Builder for custom connectors and can integrate with services like OpenAI. Airbyte is geared for data engineers and analytics engineers, with flexible deployment options and strong security, so it's a good option for anyone who needs to handle a range of data integration tasks.