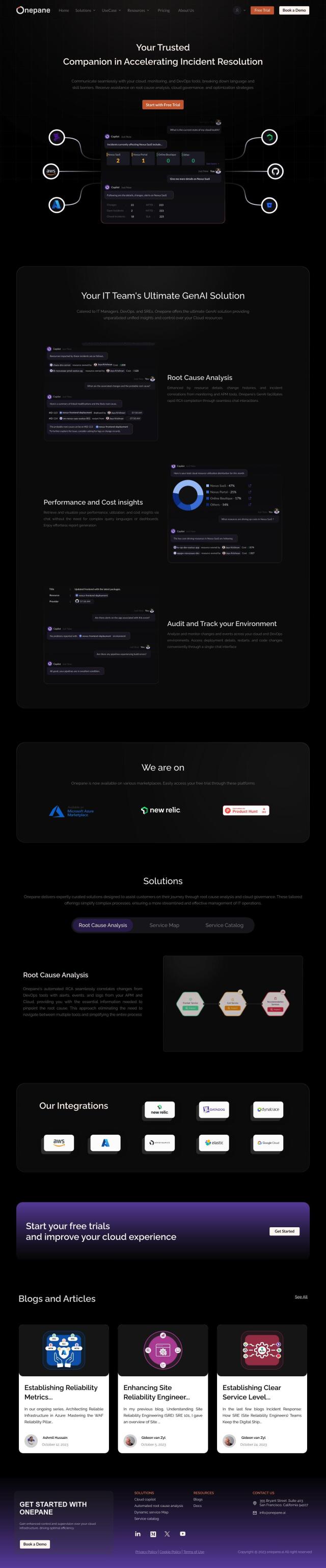
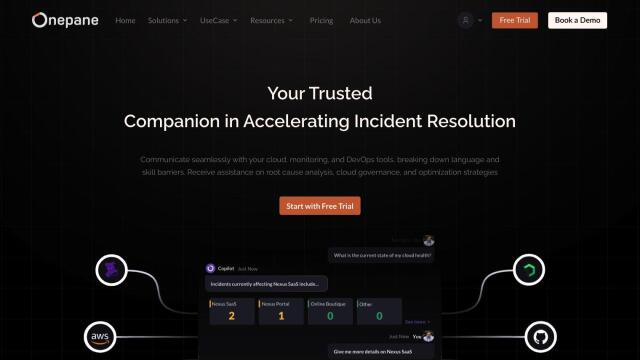
Question: I'm looking for a solution that can help me manage multiple cloud accounts and optimize resource utilization for my ML and LLM projects.
TrueFoundry
For managing multiple cloud accounts and optimizing resource usage for ML and LLM work, TrueFoundry is a good option. It speeds up ML and LLM work with faster deployment, support for both cloud and on-premise environments, and a unified management interface. It can cut production costs by 30-40% and comes with features like a model registry, one-click deployment and cost optimization, making it a good option for teams of all sizes.


Anyscale
Another option worth considering is Anyscale, which is based on the open-source Ray framework. The service supports multiple AI models, including LLMs, with features like workload scheduling, intelligent instance management and GPU and CPU fractioning for efficient use of computing resources. Anyscale can help you cut costs, too, with savings of up to 50% on spot instances, and it integrates with popular IDEs and Git tools, too, so it's a good option for large-scale AI work.


Unify
If you want to optimize LLM work, Unify offers a dynamic routing service that sends prompts to the best LLM endpoint for the job. It offers cost, latency and output speed based routing, live benchmarks for selecting providers, and a credits based pricing model. That can help you get better results and better performance by combining the best of multiple LLMs while keeping costs low.
Aiven
Last, Aiven offers a cloud-agnostic service for managing cloud computing infrastructure, supporting a range of open-source software like Apache Kafka and PostgreSQL. It offers transparent and predictable pricing, strong security and compliance options, and a 99.99% monthly uptime SLA. With its ability to deploy on multiple clouds and expert support, Aiven is good for companies that want to simplify data infrastructure and cut cloud costs.