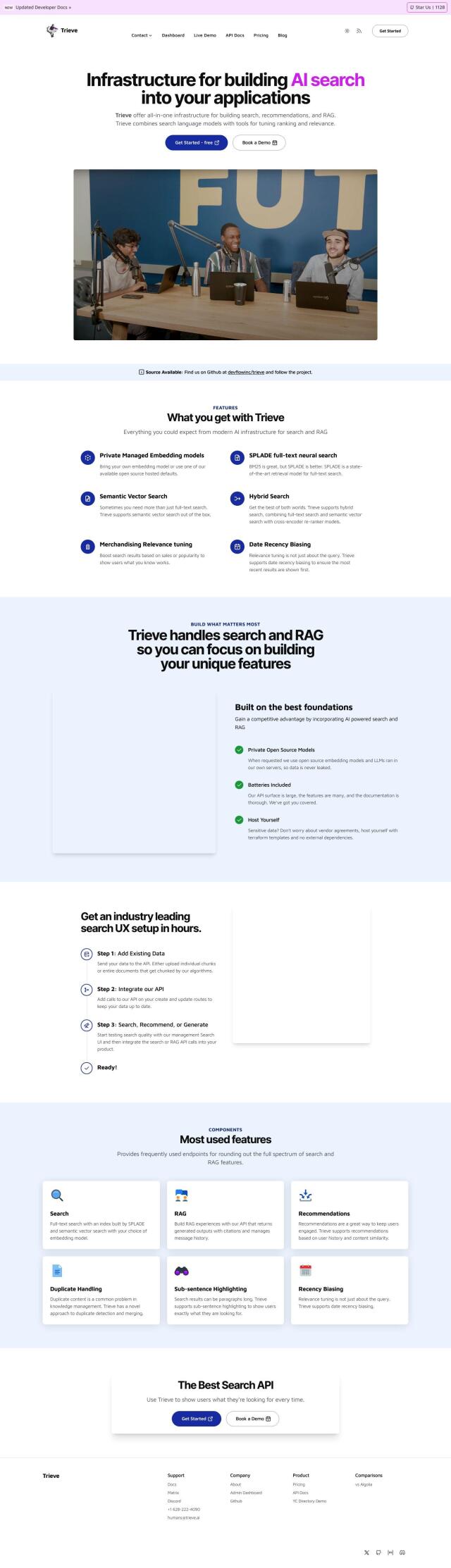
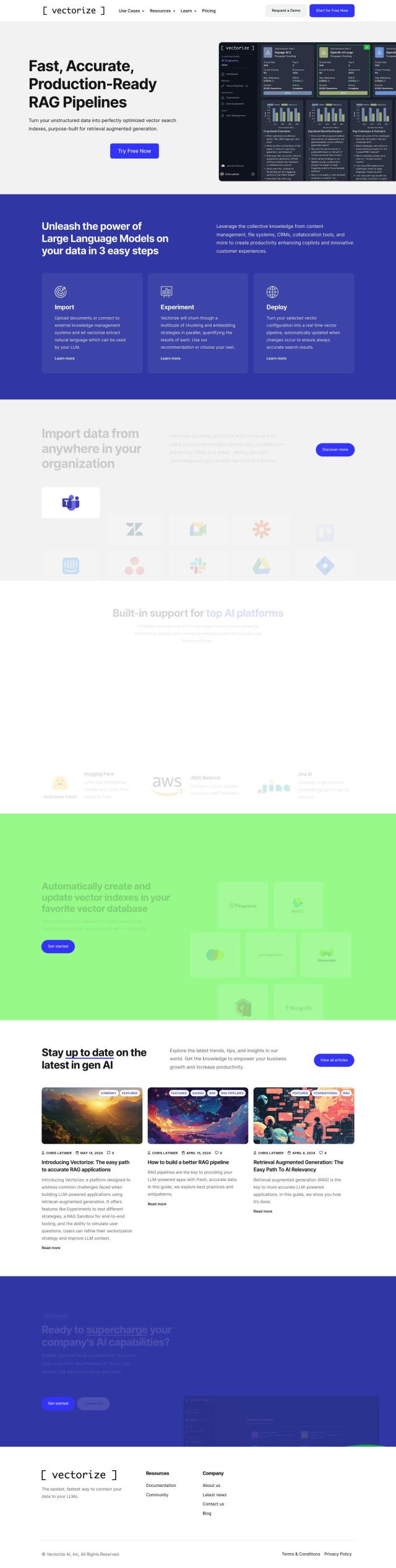
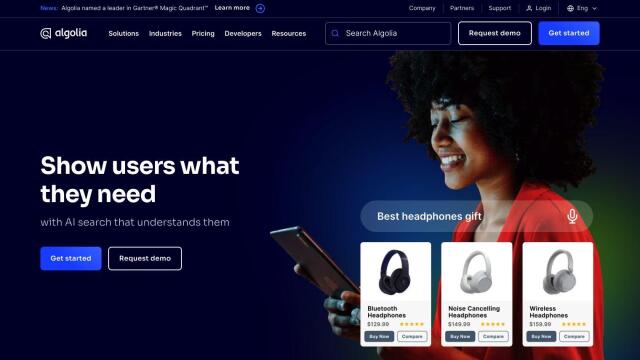
Question: I'm looking for a platform that supports low-latency vector search for search, recommendations, and detection use cases.


Pinecone
Pinecone is a vector database that's optimized for fast querying and retrieval of similar matches across billions of items in milliseconds. It has an average query latency of 51ms, 96% recall, and hybrid search that combines vector search with keyword boosting. Pinecone offers a range of pricing options, including a free starter plan, and supports major cloud providers, so it's a good option for a flexible and scalable solution.

Vespa
Vespa is a unified search engine and vector database that supports fast vector search, lexical search, and search in structured data. It's designed to build production-ready search applications at any scale, with features like machine-learned models and auto-elastic data management. Vespa is good for applications that need low latency and high end-to-end performance, and it offers free usage to get started.

Qdrant
Qdrant is an open-source vector database and search engine for fast and scalable vector similarity searches. It's designed for cloud-native architecture and integrates with leading embeddings and frameworks, so it's good for advanced search and recommendation systems. Qdrant supports flexible deployment options, including local and cloud environments, with a free tier available for small-scale use.