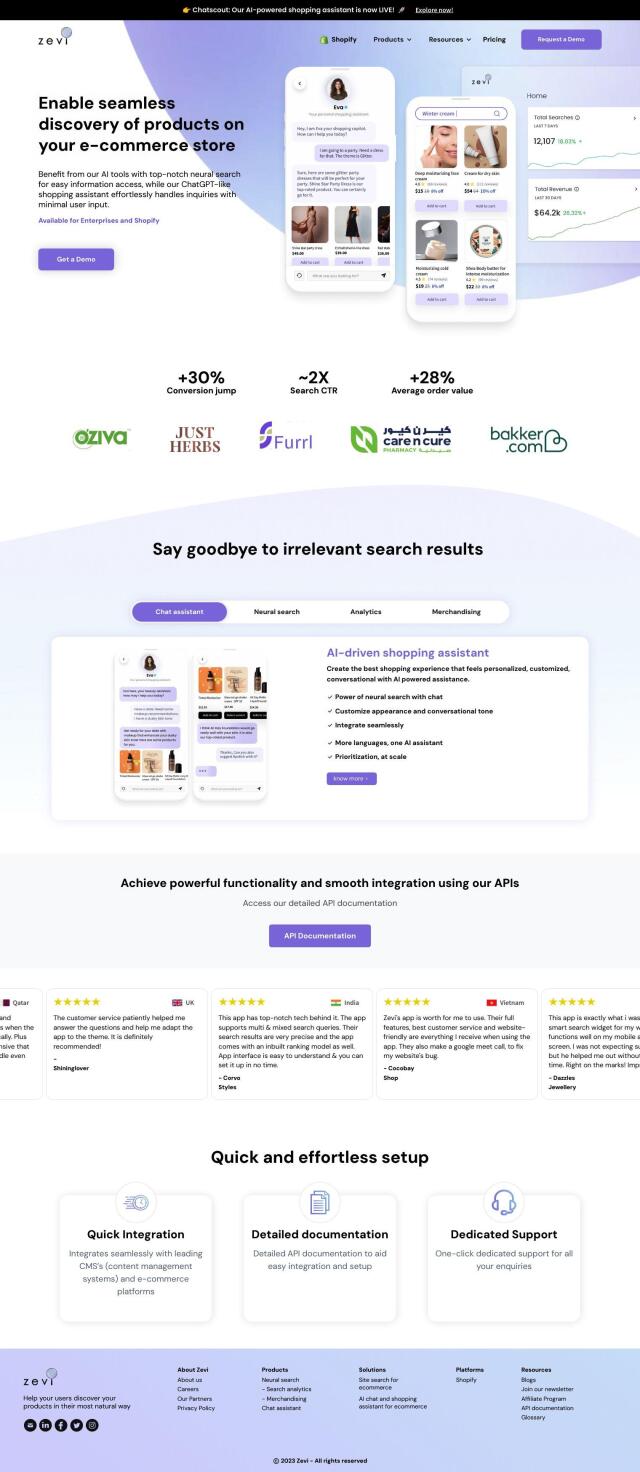
Question: I'm looking for a platform that can handle large-scale search applications with multiple features like vector search and filtering.

Vespa
If you're looking for a powerful foundation for large-scale search applications with more sophisticated features, Vespa is a great option. It's a unified search engine and vector database that supports vector search, lexical search and structured data search. Vespa is geared for high-performance and low-latency search, and it can be easily integrated with a range of machine learning tools. The platform also supports scalable and efficient model inference, making it a good fit for search, recommendation and personalization.


Pinecone
Another top contender is Pinecone, a vector database geared for fast querying and retrieval of similar matches in large data sets. Pinecone supports low-latency vector search, metadata filtering, real-time updates and hybrid search. It's designed as a serverless service, so you don't have to worry about database maintenance. Pinecone has high recall and low query latency, which means it's a good option for applications that need to deliver results fast and accurately.

Qdrant
If you prefer an open-source option, Qdrant is a scalable vector database and search engine built for cloud-native architecture. Qdrant is geared for high-performance processing of high-dimensional vectors and can be integrated with leading embeddings and frameworks. It's available in a variety of deployment options, including a free tier, and can be used for a range of use cases, including advanced search and recommendation systems.
Trieve
Last, Trieve is a full-stack infrastructure for building search, recommendations and RAG experiences. It supports semantic vector search, hybrid search and offers private managed embedding models. Trieve is geared for advanced search use cases and offers flexible deployment options, including self-hosting and cloud services, so it's a good option for developers.