Question: I need a resource that provides access to a large catalog of open datasets for my data science projects.


Hugging Face
If you want a single resource with a big catalog of open datasets, Hugging Face is a good choice. The site has more than 100,000 public datasets for different tasks, along with tools for collaboration and application development. It also offers unlimited hosting and features like optimized compute options and private dataset management for enterprise customers.
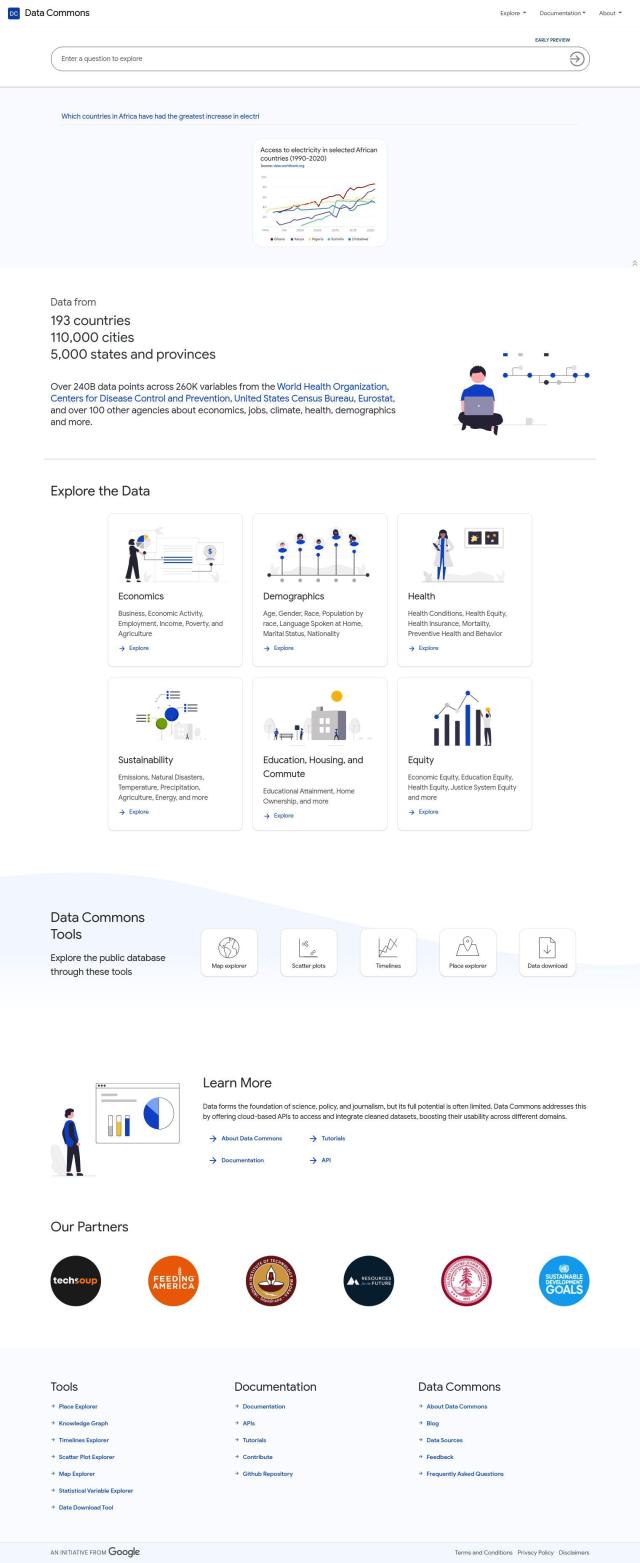
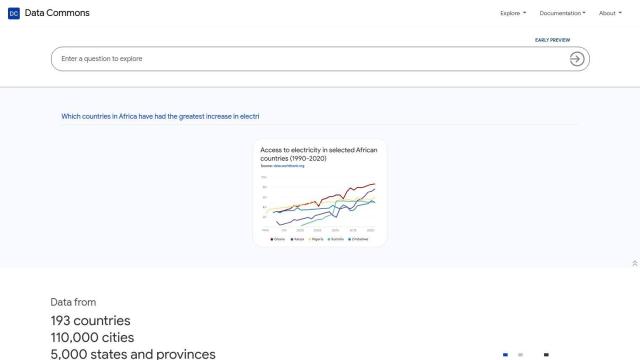
Data Commons
Another good resource is Data Commons, which collects data from more than 193 countries and 5,000 states and provinces. It covers a lot of subjects and offers tools like a map explorer, scatter plots and timelines to help you visualize the data. With 240 billion data points and 260,000 variables, it's geared for scientists, policymakers and journalists.
Kaggle
Kaggle is also a good site for data science projects. It's got a vast library of open source datasets, pre-trained models and cloud-based notebooks for collaborative analysis. Kaggle is good for data scientists and students, with a community where you can share and learn from others' projects.
Opendatasoft
If you need a single site to house and share data, Opendatasoft is a good choice. It's got features like self-service access, AI-driven user experience and powerful data management. It's flexible enough to accommodate different use cases like internal data portals and open data programs, so data is easily consumable at large scale.