Question: Do you know of a tool that provides high-throughput inference for large language models, with guaranteed JSON output and high accuracy?


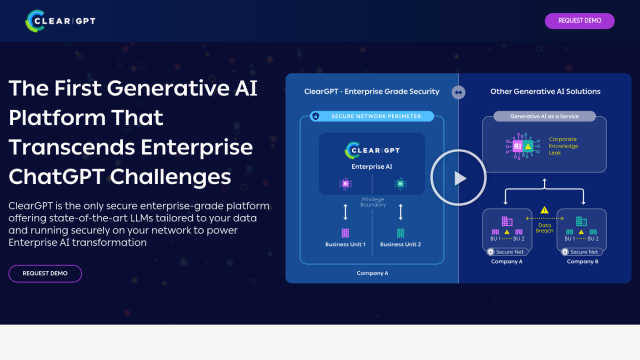
Lamini
If you're looking for a tool that offers high-throughput inference for large language models with guaranteed JSON output and high accuracy, Lamini is a good option. It's an enterprise-focused platform for software teams to create, manage and run their own LLMs. Lamini offers features like memory tuning for high accuracy, deployment on different environments, including air-gapped ones, and guaranteed JSON output. It can be installed on-premise or in the cloud and can handle thousands of LLMs, so it's a good choice for large-scale AI workloads.
Groq
Another good option is Groq, which offers an LPU Inference Engine that offers high-performance, high-quality and energy-efficient AI compute. It can be deployed in the cloud or on-premise, so it's adaptable to different scaling needs. Groq's platform is optimized for efficiency, which can cut energy costs while keeping AI inference fast.


Together
Together is also an option. It's a cloud platform for fast and efficient development and deployment of generative AI models. It includes new optimizations like Cocktail SGD and FlashAttention 2 to accelerate training and inference. Together supports a variety of models and offers scalable inference, so it's good for high traffic volumes at a low cost.


Predibase
For a more affordable option, Predibase offers a developer-focused platform for fine-tuning and serving LLMs. It offers a low-cost serving infrastructure and free serverless inference for up to 1 million tokens per day. Predibase supports multiple models and uses a pay-as-you-go pricing model, so it's a good option for developers who want to deploy LLMs without a lot of hassle.