Question: I'm looking for a tool that can help me create high-performance retrieval workflows for my AI applications, do you know of any?


Pinecone
If you need a service to build high-performance retrieval workflows for your AI projects, Pinecone is a top contender. Pinecone is a vector database geared for fast querying and retrieval, with low-latency vector search, metadata filtering and real-time indexing. It scales automatically with no database administration required, so it's a secure, enterprise-ready option with several pricing plans and abundant documentation to help you get up and running.
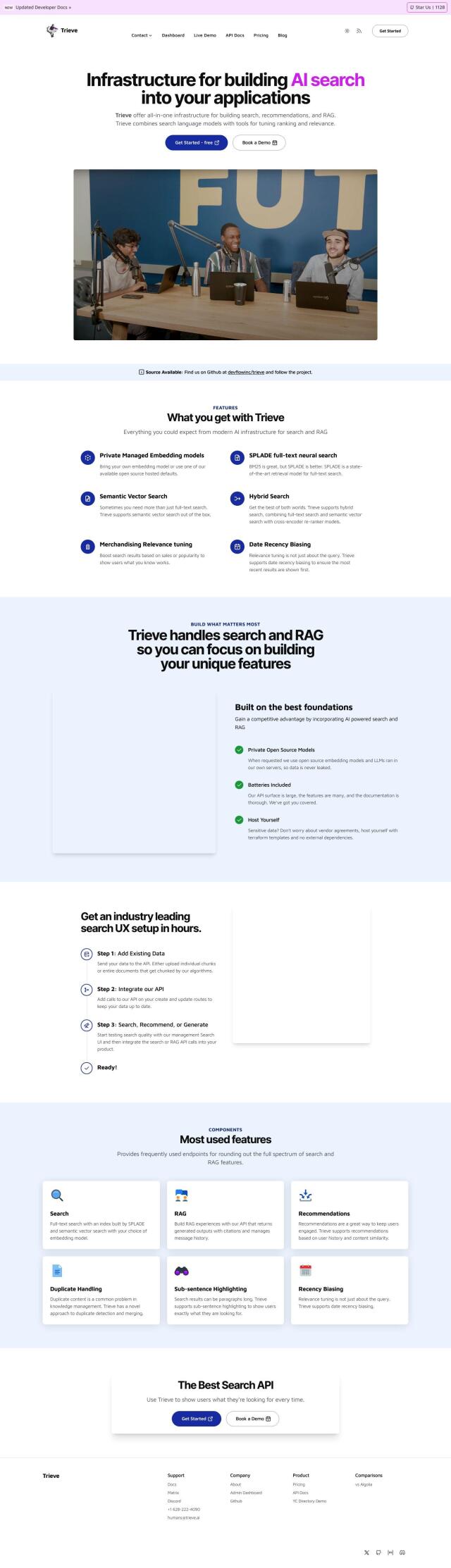
Trieve
Another good choice is Trieve, which offers a full-stack foundation for building search, recommendations and RAG experiences. Trieve combines private managed embedding models, SPLADE full-text neural search and semantic vector search, so it's good for more advanced search use cases. It lets you host private data and offers several hosting options, including a free tier for noncommercial use.
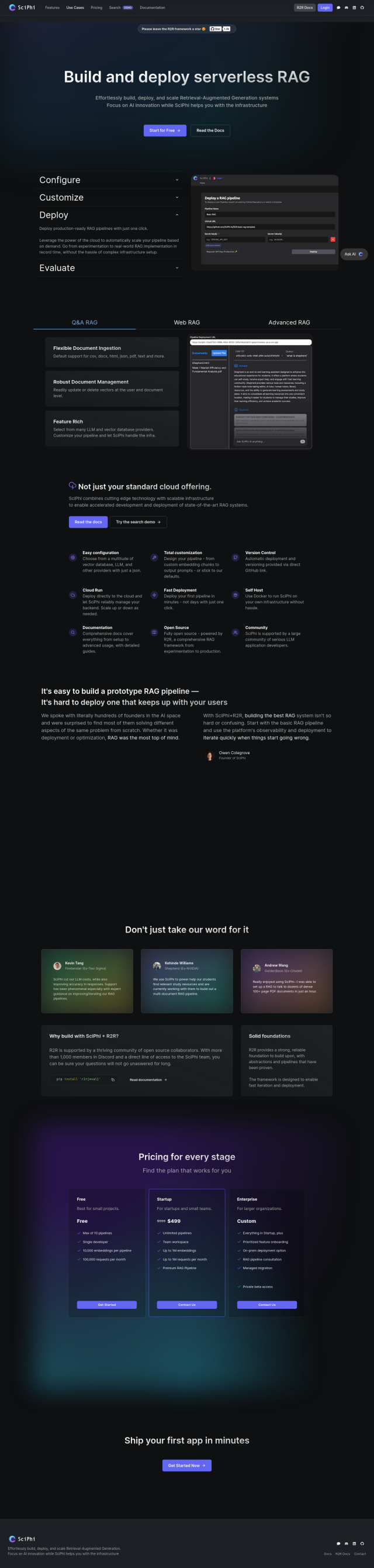
SciPhi
SciPhi is another option. This information retrieval system lets you ingest documents flexibly, manage them heavily and scale dynamically, so you can run state-of-the-art RAG system methods. SciPhi offers several pricing tiers and is open-source, so it's adaptable and relatively inexpensive for a range of AI tasks.

Qdrant
Last is Qdrant, an open-source vector database and search engine for high-performance vector similarity searches. Built for a cloud-native architecture and written in the Rust programming language, Qdrant offers cloud-native scalability and high availability. It can be integrated with leading embeddings and frameworks, and offers flexible deployment options and strong security, making it a good foundation for developers.