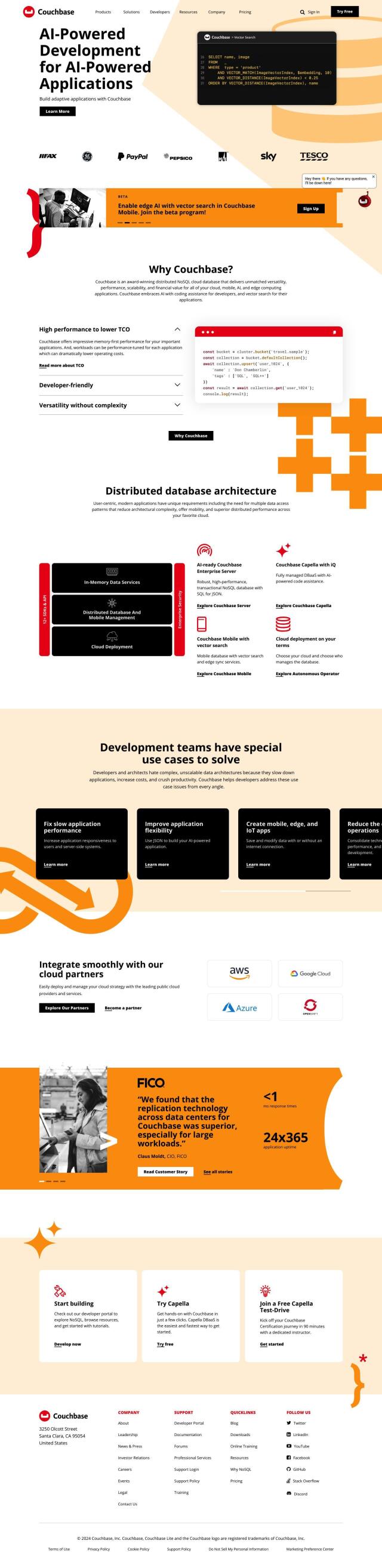
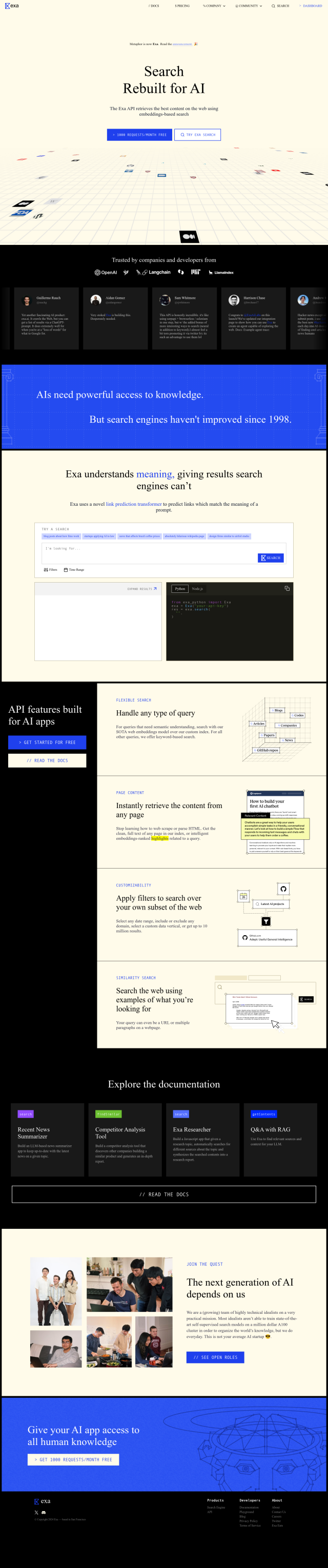
Question: Looking for a flexible, high-performance search solution that can integrate with machine learning and data processing tools.

Vespa
If you need a flexible, high-performance search engine that's tightly integrated with machine learning and data processing tools, Vespa is worth a look. It's a unified search engine and vector database that can handle different types of search, including vector, lexical and structured data. Vespa's ability to combine those in a single query is a big selling point, as is its support for scalable and efficient machine-learned model inference. It also can be integrated with a variety of machine learning tools and has auto-elastic data management, which means high end-to-end performance and low latency.
Trieve
Another good option is Trieve, which offers a full-stack infrastructure for building search, recommendations and RAG experiences. It offers advanced search features like semantic vector search, private managed embedding models and hybrid search. Trieve is AI-powered and lets customers use their own embedding models or use open-source defaults, so it's adaptable to a range of use cases. It offers free tiers and paid options, as well as 24/7 support.

OpenSearch
If you're looking for an open-source option, OpenSearch is a flexible and customizable foundation. It offers features like geospatial indexing, alerting, SQL/PPL support, k-NN/vector database support and learning to rank. OpenSearch is well-suited for high-performance search and supports a wide range of infrastructure, making it a good option for the enterprise. It also comes with a collection of tools and plugins to expand its abilities in areas like analytics, security and machine learning.

Qdrant
Last, Qdrant is an open-source vector database and search engine geared for fast and scalable vector similarity searches. It offers cloud-native scalability and high-availability, making it a good option for advanced search and recommendation systems. Qdrant can be integrated with leading embeddings and frameworks, and offers flexible deployment options, including a free tier, so it's a good option for developers who need high-performance vector search.