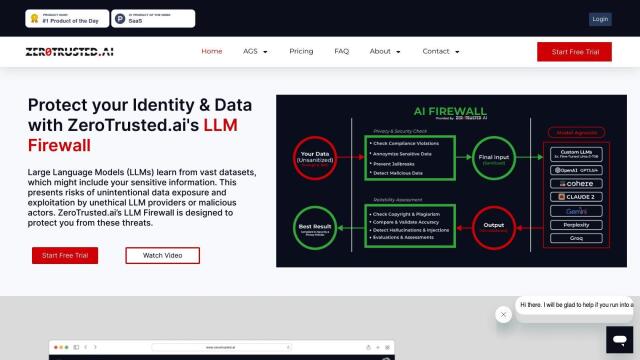
Question: How can I ensure the accuracy of my AI model's responses, is there a tool that can detect hallucinations and improve answer relevance?


LastMile AI
To get your AI model to give you accurate answers and to spot hallucinations, LastMile AI is a good option. The platform includes features like Auto-Eval for automated hallucination detection and evaluation, RAG Debugger for optimizing performance, and AIConfig for version control and prompt optimization. It can handle a variety of AI models, including text, image and audio, so it can be used for a variety of tasks.

Deepchecks
Another option is Deepchecks, which automates evaluation and can spot problems like hallucinations, incorrect answers and bias. It uses a "Golden Set" approach that combines automated annotation with manual overrides to create a detailed ground truth for your LLM applications. It's designed to let you build LLM software more quickly and ensure your LLMs give you useful, accurate answers.

HoneyHive
For a more general-purpose evaluation and testing tool, look at HoneyHive. HoneyHive offers an LLMOps environment for collaboration, testing and evaluation, including automated CI testing and observability. It supports more than 100 models, and features like dataset curation, prompt management and distributed tracing make it useful for debugging and optimizing AI applications.

LangWatch
Last, LangWatch is designed to ensure the quality and safety of generative AI services. It can help you avoid problems like hallucinations and leakage of sensitive data, and offers real-time metrics for conversion rates and user feedback. LangWatch is geared for developers, product managers and anyone else who's building AI applications that need to meet high quality and performance standards.