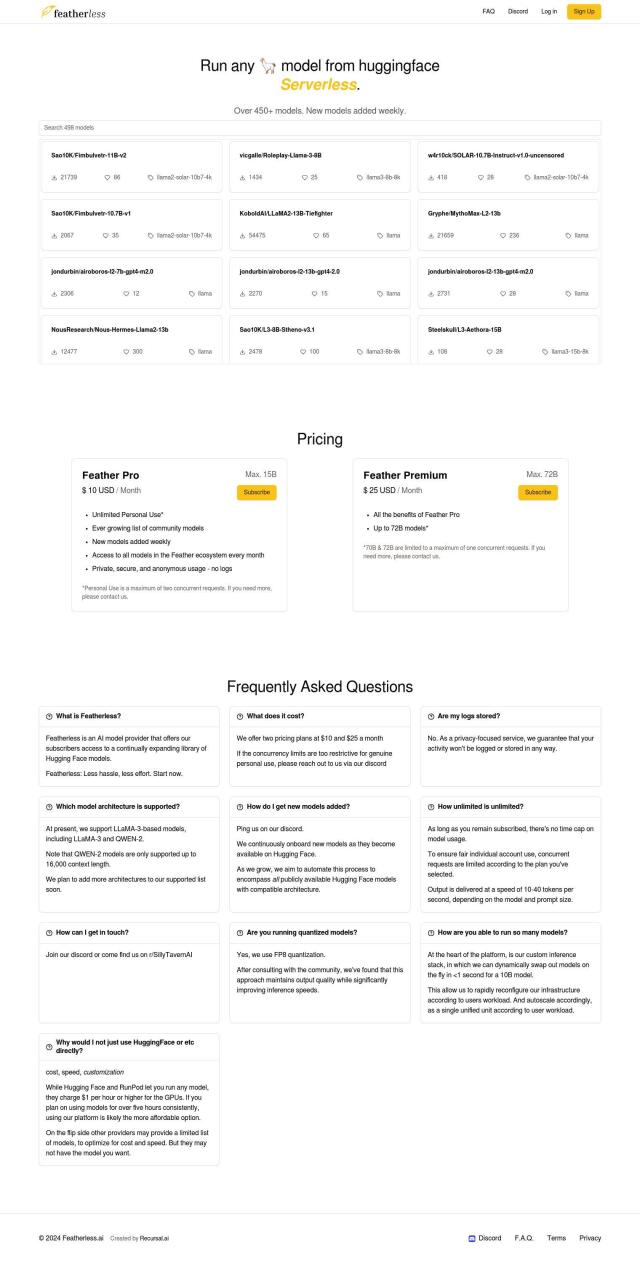
Question: Is there a cost-effective LLM inference API that doesn't charge per token?

Awan LLM
If you're looking for an LLM inference API that's cheap and doesn't charge by the token, Awan LLM is worth a look. The service has unlimited tokens with no limits or censorship, and pay-as-you-go pricing means no per-token costs. It supports a range of models, and there are several pricing tiers to accommodate different needs, so you can mix and match to get what you need at a price you like.


Predibase
Another good option is Predibase, which charges by model size and dataset. It offers free serverless inference for up to 1 million tokens per day, which is a good option for developers. Predibase also supports a range of models, and it offers enterprise-level security and dedicated deployment options.

Kolank
If you want to query a fleet of LLMs through a single API, Kolank has a smart routing algorithm that sends your prompts to the most accurate model. The service is designed to minimize latency and reliability problems while cutting costs by sending prompts to cheaper models when possible, so it's a good option for developers who want to get the best of both worlds.