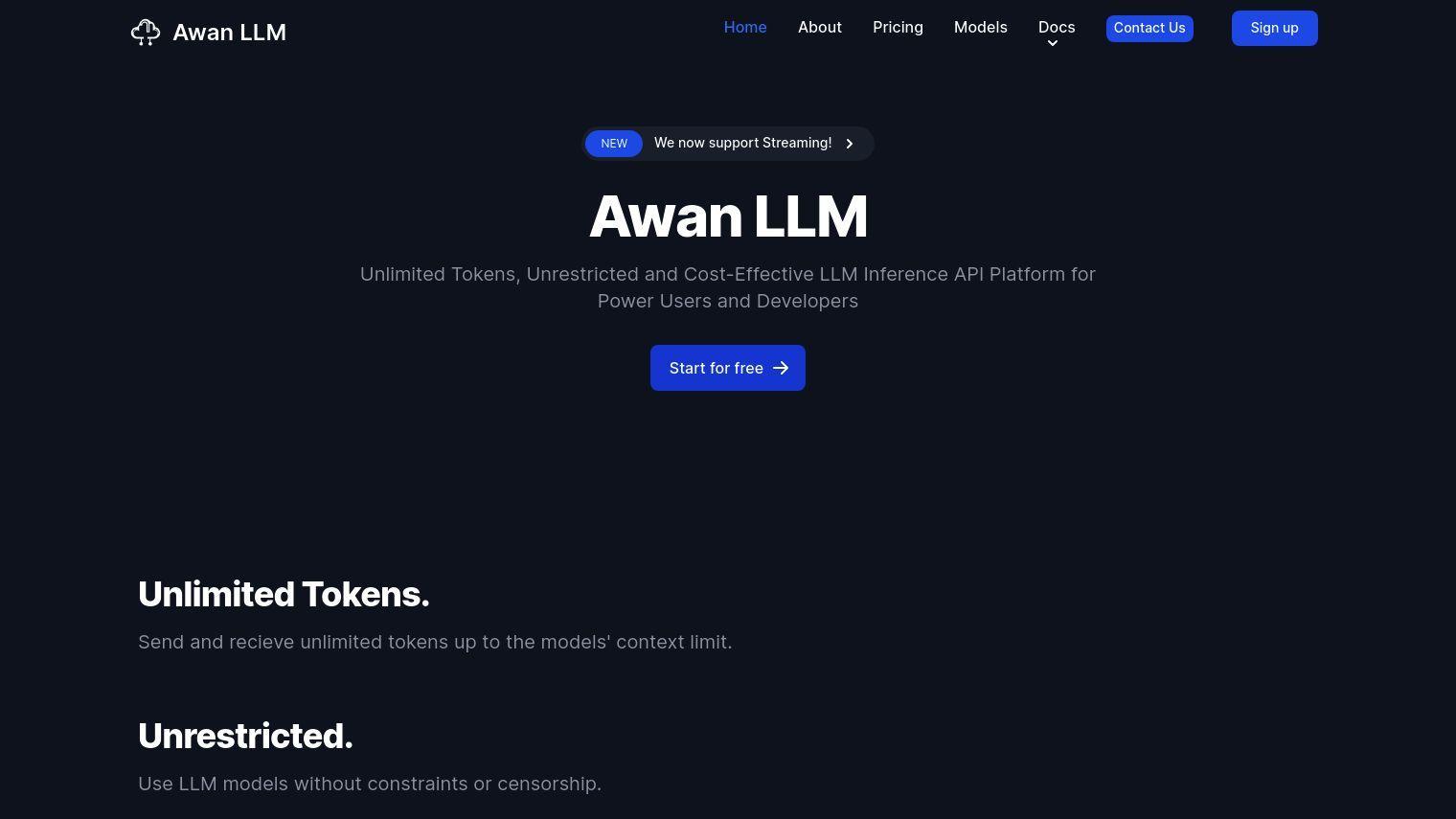
Awan LLM is an LLM Inference API platform that offers unlimited tokens with no limits or censorship. By operating its own data centers and GPUs, Awan LLM offers a cost-effective option with no per-token fees. This is particularly useful for power users and developers who need to interact with AI extensively.
Some of the main features of Awan LLM include:
- Unlimited Tokens: Send and receive tokens up to the models' context limit without any limits.
- Unrestricted: Use LLM models without any limits or censorship, great for any use case.
- Cost-Effective: Pay by the month instead of by the token, saving money for users.
- Assistant: Use an AI assistant without any token limits.
- AI Agents: Let agents run indefinitely without worrying about token limits.
- Roleplay: Go on epic adventures with AI friends without token limits.
- Data Processing: Process lots of data fast and efficiently.
- Code Completion: Write code faster and better with unlimited completions.
Awan LLM offers a variety of pricing tiers to suit different needs:
- Lite: Free, great for testing and personal use, with 20 requests per minute and limited model access.
- Core: $5/month, great for personal use, with 20 requests per minute and more model access.
- Plus: $10/month, great for enthusiasts, with 50 requests per minute and more model access.
- Pro: $20/month, great for power users and startups, with parallel requests and more model access.
- Max: $80/month, great for big projects and small businesses, with parallel requests and unlimited model access.
- Enterprise: Custom pricing for big projects, with guaranteed generation speed and service-level agreements.
Awan LLM supports a range of models, including Meta-Llama-3-8B-Instruct, Llama 3 Instruct, and WizardLM-2-8x22B, each designed for different use cases like general use, storywriting, and instruction following. Users can easily integrate these models with the provided API endpoints and quick-start guides.
For those interested in using Awan LLM, the platform offers a simple onboarding process through its Quick-Start page and clearly explained request rate limits. There are no hidden token limits, but users can request more models if they're not available on the platform. Awan LLM prioritizes user privacy by not logging prompts or generations, as described in its Privacy Policy.
Published on July 23, 2024
Related Questions
Tool Suggestions
Analyzing Awan LLM...