Question: I need a tool that can identify speakers in an audio file, do you have any suggestions?

AssemblyAI
For identifying who's speaking in an audio file, AssemblyAI has a powerful option. Speaker detection is an option built into its full-featured speech-to-text transcription service. It's got a free tier for prototyping and pay-as-you-go pricing, so it's a good option for companies building AI products that use voice data. AssemblyAI has strong security and privacy protections, too, so it's a good option for sensitive data.

Vocapia
Another good option is Vocapia, which offers high-performance speech recognition and speaker identification with AI-based machine learning technology. The VoxSigma software suite is geared for serious customers who need to transcribe lots of audio and video documents. It works in 25 languages and offers pricing that scales by the length of the speech, with free trials.

WavoAI
WavoAI also can identify speakers, along with transcribing audio more quickly and in context. It's a general-purpose tool that can be used in a variety of industries and situations, from academics to podcasters. WavoAI is designed to be integrated into other tools and has flexible pricing options, so it can be a good addition to what you already have.
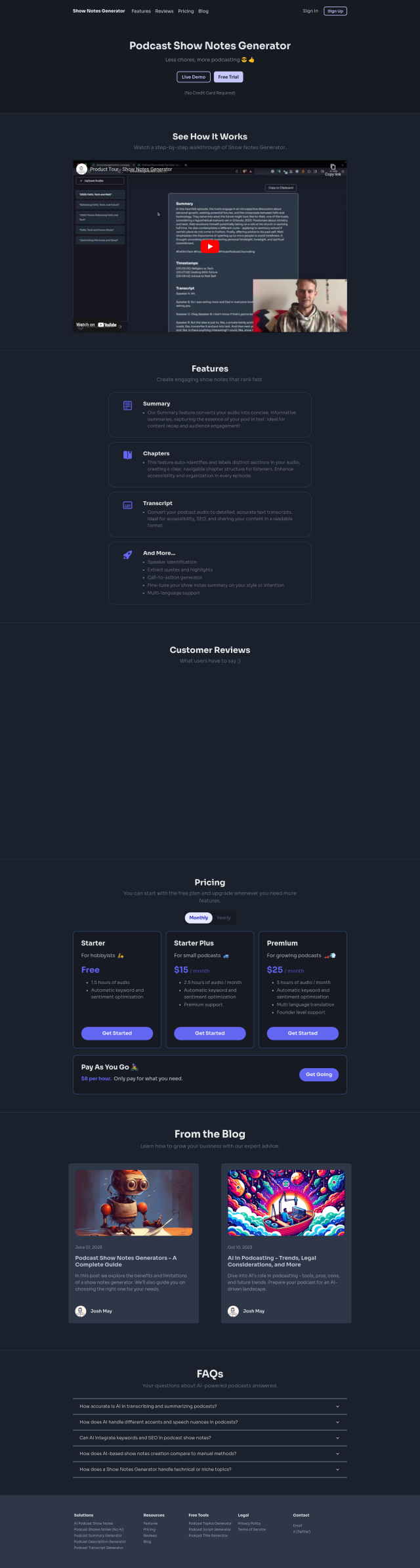
Podcast Show Notes Generator
For podcasters, Podcast Show Notes Generator is worth a look. It automates speaker identification, chapter labeling, transcript generation and content creation. It can handle multiple languages and has several pricing tiers, so it's good for both new and experienced podcasters.