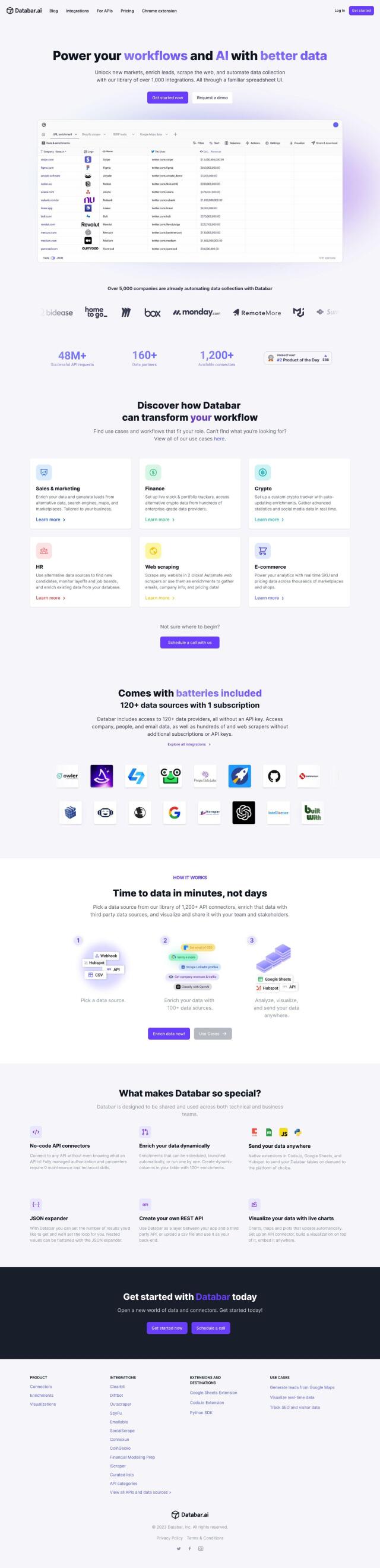
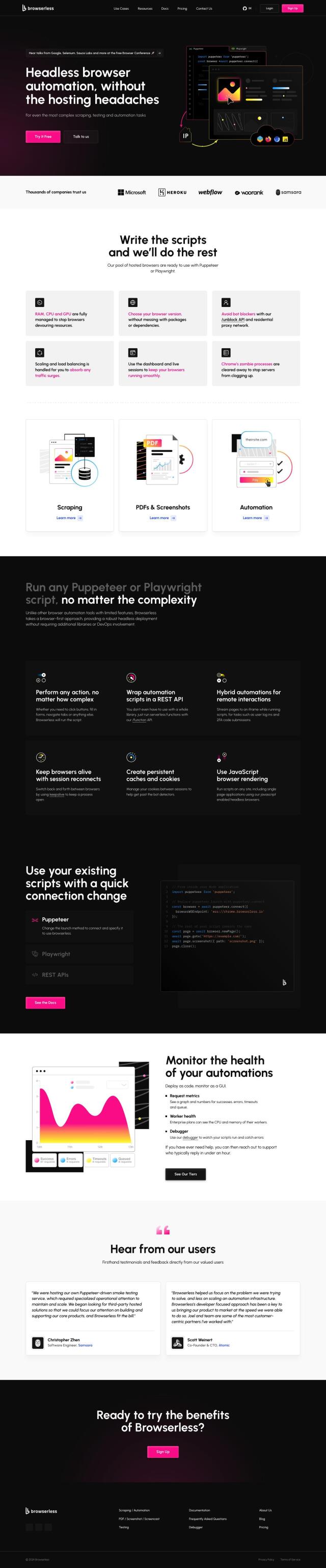
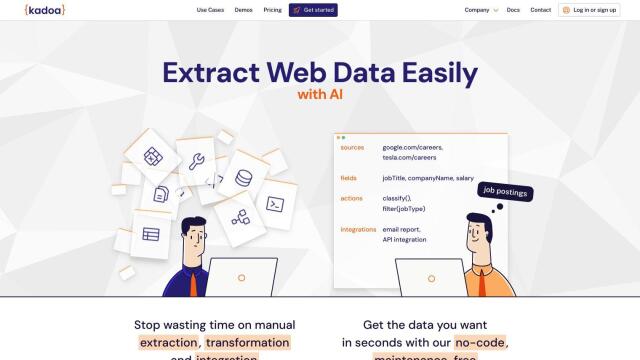
Crawlbase Alternatives


Bright Data
If you're looking for a Crawlbase alternative, Bright Data could be a good choice. The platform provides a range of tools for web data scraping, including a network of 72 million+ residential proxy IPs, automated session control and tools to bypass CAPTCHAs. It also offers actionable retail competitive intelligence and is designed to comply with strict privacy regulations, so it's good for e-commerce and other industries.

Apify
Another good alternative is Apify, a cloud-based web scraping and browser automation service. With more than 1,600 pre-built tools and a pay-as-you-go pricing model, Apify makes it easy to scrape websites, with support for multiple libraries and proxy management. It's geared for businesses and developers who want to automate web scraping and browser automation tasks.
Zyte
If you prefer a more AI-boosted approach, Zyte provides an integrated service for managing web data extraction with intelligent proxies and browsers. It can handle a range of data formats and offers customized pricing plans depending on the complexity of websites and the number of requests. That means it's a good option for businesses that need high accuracy and performance for web data extraction.

ScrapingBee
Last, ScrapingBee offers a web scraping API that controls headless browsers and proxies, letting you extract data from websites regardless of how complex they are. It supports JavaScript scraping and offers a range of pricing options to suit different businesses, including a no-code option through Make integration. That can be useful for businesses that need to scrape data from websites that are heavily reliant on JavaScript.