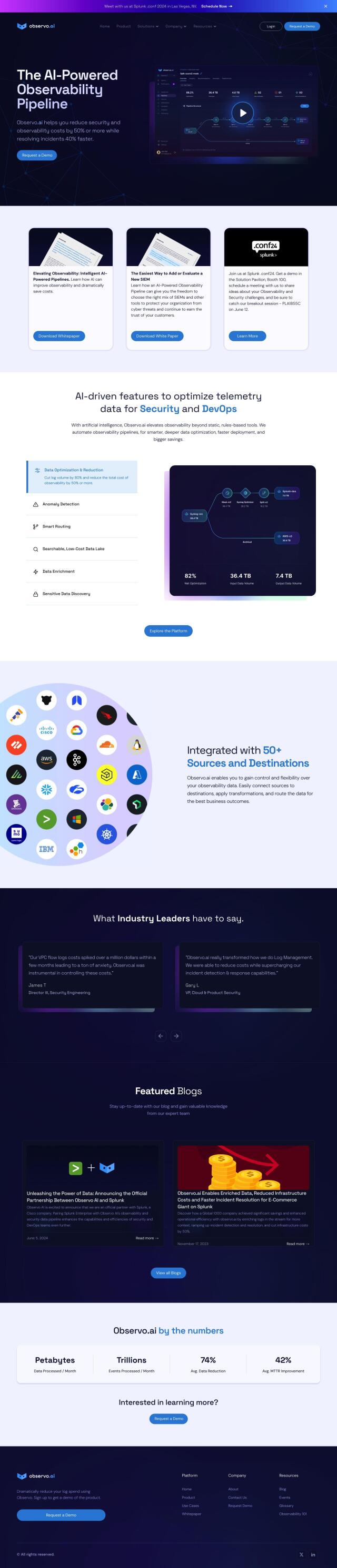
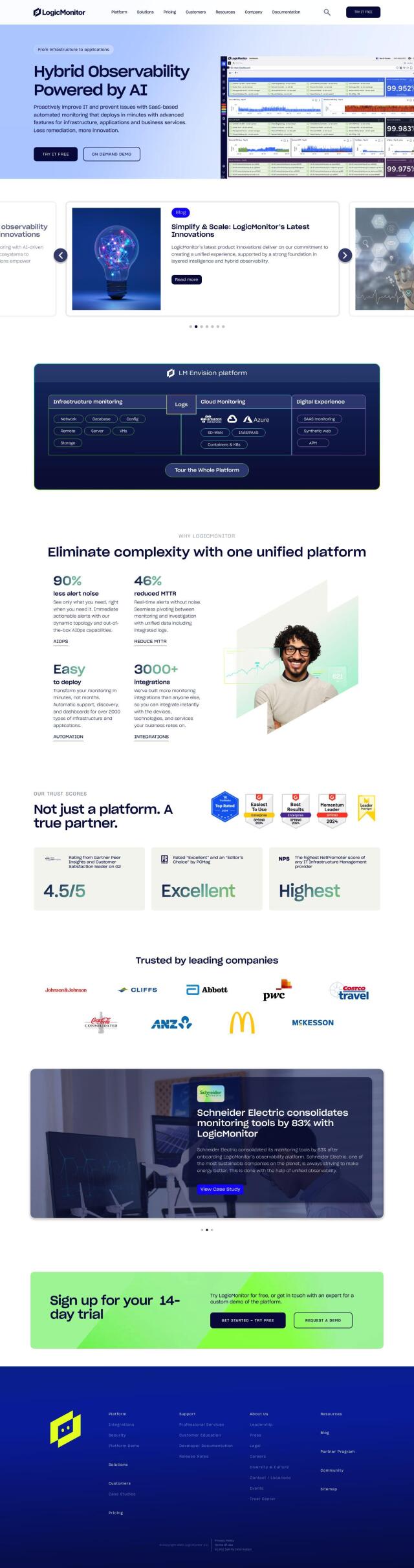
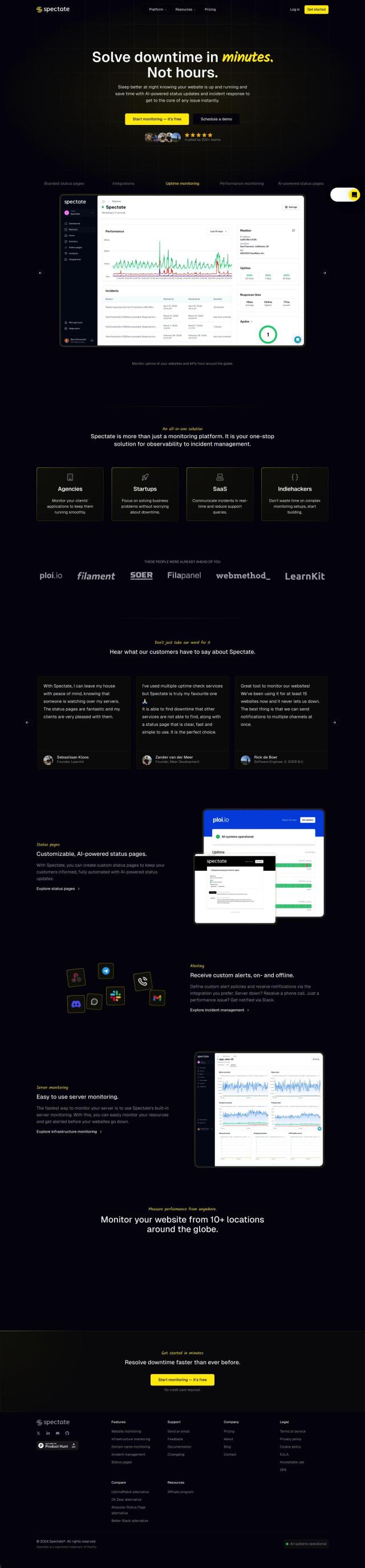
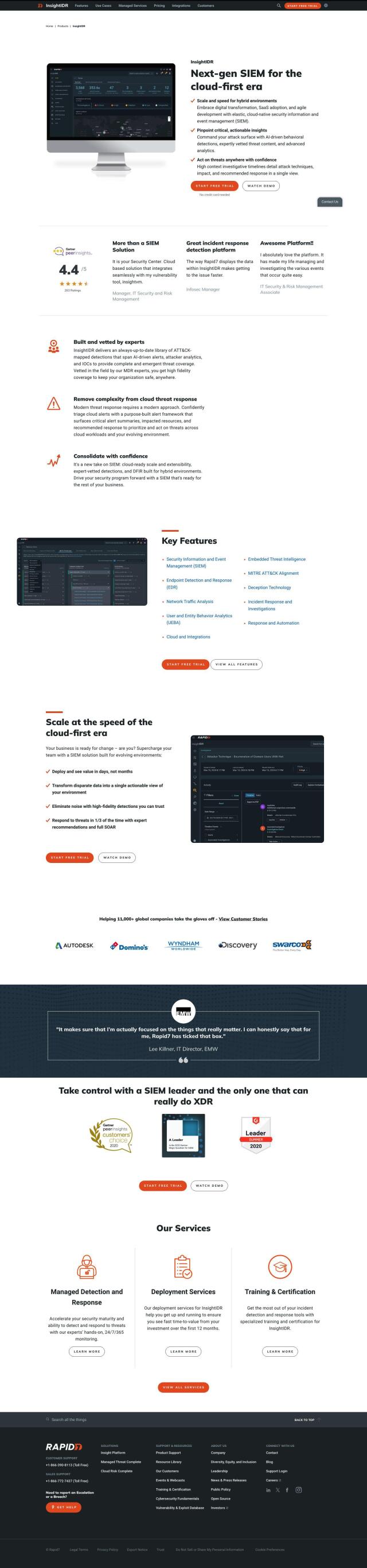
Better Stack Alternatives


Logz.io
If you're looking for a Better Stack alternative, Logz.io could be a good option. It aggregates open-source monitoring tools like OpenSearch, Prometheus, and OpenTelemetry for logs, metrics and distributed tracing. AI-based anomaly detection and alert recommendations can help you get to the bottom of issues faster, reducing mean time to resolution (MTTR). It integrates with more than 300 services and offers flexible pricing.
Honeycomb
Another good option is Honeycomb. The service lets teams pinpoint the source of problems in distributed services with features like custom attributes for debugging, smart data sampling and debuggable Service Level Objectives (SLOs). It can handle unlimited custom attributes and event data, so it's good for teams of any size. Honeycomb's AI-powered query assistant and Slack integration for real-time triage also can speed up incident resolution.
Edge Delta
If you want an observability service that's automated, check out Edge Delta. It can analyze petabytes of data with AI, provide real-time insights automatically and use AI/ML for anomaly detection. Edge Delta has flexible data pipelines for ingestion and transformation so you can handle the data you need and avoid the ones you don't. Its interface is designed to be easy to use, and its distributed architecture means you can query log data fast and scale to meet your needs.
Datadog
Last, Datadog is an all-in-one monitoring and security service that can give you real-time visibility into performance, security and user experience for any technology stack. It's got a lot of features, including infrastructure monitoring, APM, synthetic monitoring and serverless monitoring, so it's good for teams that want to monitor their full tech stack.