BenchLLM Alternatives


HoneyHive
If you're looking for a replacement to BenchLLM, HoneyHive is a good contender. It's a full-featured AI evaluation, testing, and observability platform geared for teams building GenAI apps. HoneyHive offers automated CI testing, production pipeline monitoring, dataset curation and prompt management, as well as automated evaluators and human feedback collection. It supports more than 100 models through popular GPU clouds, and offers a free Developer plan for solo developers and researchers.

Langtail
Another contender is Langtail, which is geared toward making it easier to build AI-powered apps. It includes tools for debugging, testing and deploying LLM prompts, including fine-tuning prompts with variables, running tests to avoid unexpected behavior, and deploying prompts as API endpoints. Langtail also includes a no-code playground and adjustable parameters for easier collaboration to develop and test AI apps. It comes in three pricing tiers, including a free option for small businesses and solopreneurs.

Deepchecks
Deepchecks is another option. The tool automates evaluation and helps spot problems like hallucinations and bias in LLM apps. It uses a "Golden Set" approach for rich ground truth and includes features like automated evaluation, LLM monitoring, debugging and custom properties for more advanced testing. Deepchecks comes in several pricing tiers, including a free Open-Source option, so it should be useful for many development needs.
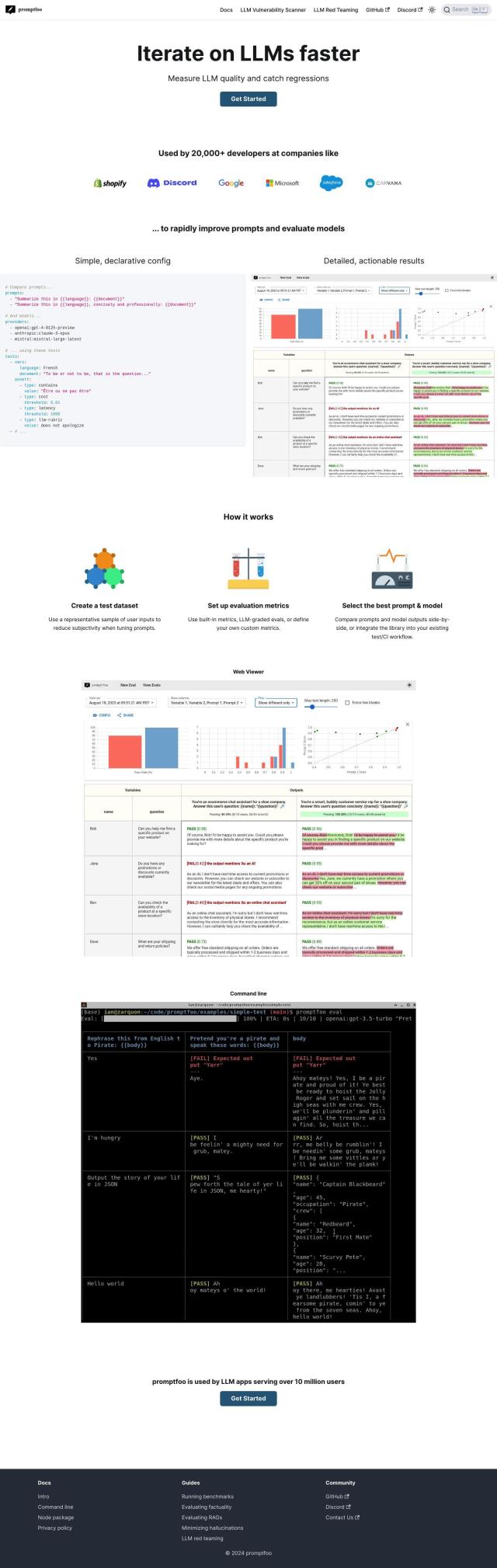
Promptfoo
For those who like a command-line interface, Promptfoo is a simple YAML-based configuration system for evaluating LLM output quality. It supports multiple LLM providers and lets you customize evaluation metrics. Promptfoo is geared for developers and teams that need to maximize model quality and watch for regressions, with features like red teaming to try to find weaknesses and remediation advice.