Question: Is there a service that can help me scrape search engine result pages, including Google, without having to manage proxies and headless browsers?

ScrapingBee
If you're looking for a service to scrape search engine result pages, including Google, without having to worry about proxies and headless browsers, ScrapingBee could be a good option. It's a full featured web scraping API that handles the ins and outs of headless browsers and proxies so you can focus on extracting data from websites that use complex JavaScript, like those built with React, AngularJS or Vue.js. ScrapingBee offers a variety of pricing plans and a pretty generous free tier, so it's pretty easy to get started.
Zyte
Another good option is Zyte, an AI-powered web scraping service that handles the proxy and browser details for you. Zyte can handle a variety of data formats, and it offers managed data extraction plans that you can customize to your needs. Zyte's smart proxies and browsers are designed to maximize data extraction accuracy and speed, making it a good choice for businesses and developers.
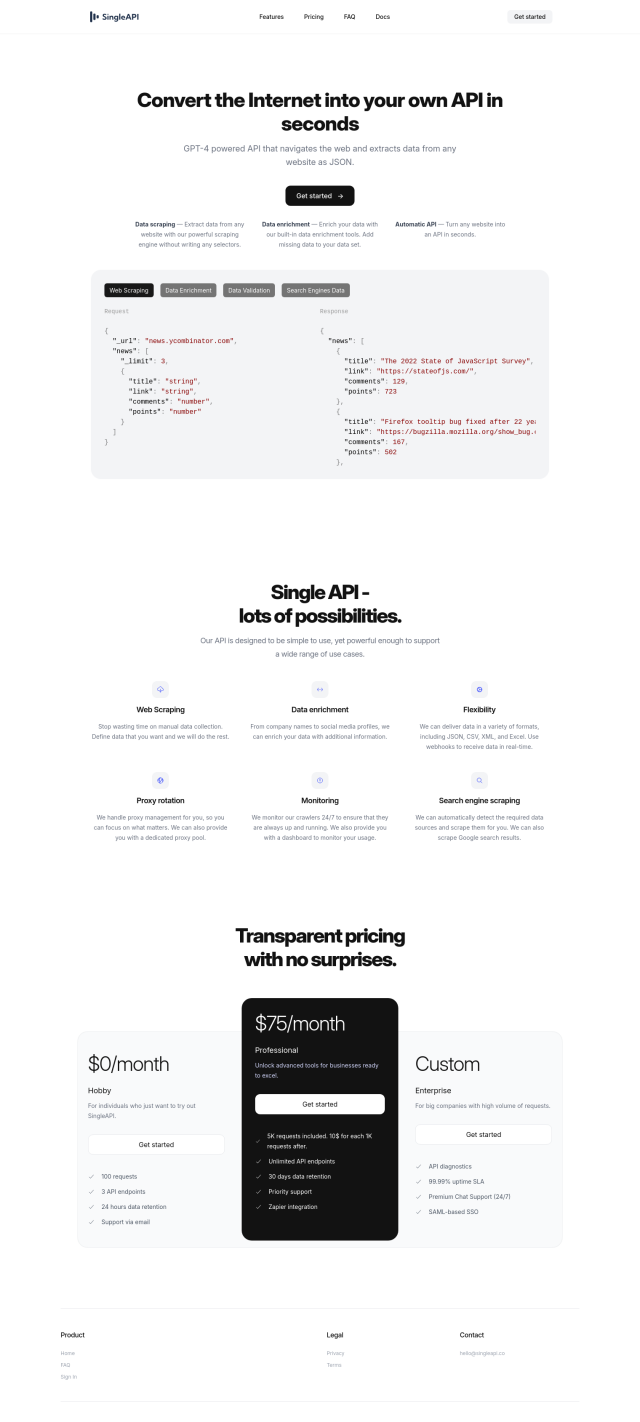
SingleAPI
If you want to take a more automated approach, check out SingleAPI, which uses GPT-4 technology to turn any website into an API with a single click. It can handle a variety of data formats, and it offers automated proxy rotation and real-time webhooks. SingleAPI's search engine scraping feature can automatically detect and scrape Google search results, so it's a good option for anyone who needs to scrape search engine data.

Bright Data
Last, Bright Data is a general purpose web data collection service that includes a large pool of residential proxy IPs and tools to bypass blocks and CAPTCHAs. The service is designed to ensure ethical data collection practices and can be used in a variety of industries, including e-commerce and social media. Bright Data's dynamic browser and proxy management tools make it a good option for more general purpose web data scraping.