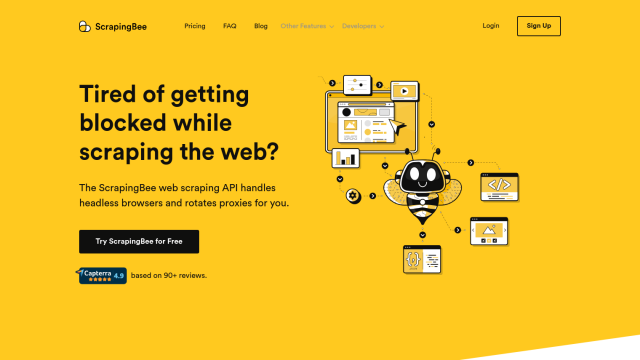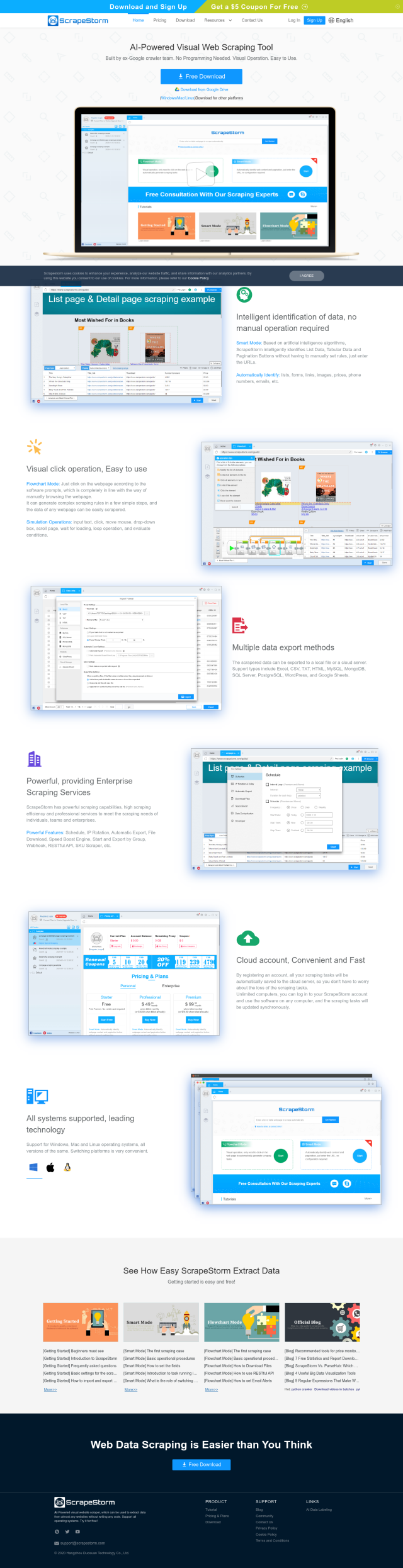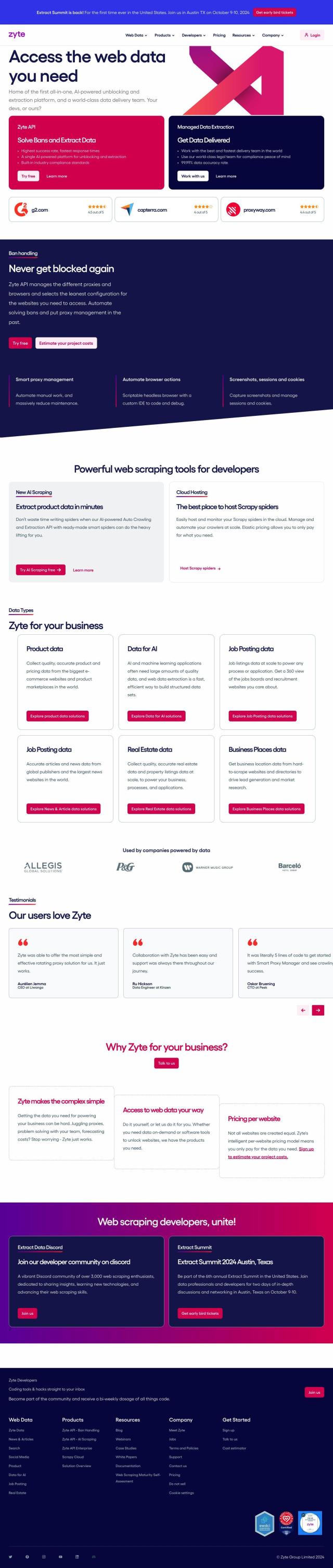

ScrapeNinja is a web scraping API that lets you quickly and easily extract data from websites at scale. It automates complex tasks like headless browsers, proxies, timeouts and retries so you can focus on getting data in JSON format.
ScrapeNinja's main features include:
- Headless Browser Management: Handles browsers so you don't have to.
- Proxy Integration: Uses proxies to avoid IP blocking.
- Timeout and Retry Handling: Keeps running even if things go wrong.
The tool is geared for developers and data analysts who need to pull data from lots of websites. ScrapeNinja is integrated with RapidAPI, which makes it easy to sign up and start scraping. There's also detailed documentation and a getting started guide to help you get up and running as quickly as possible.
Pricing information is on the site, along with a sample scraper you can use to try out ScrapeNinja. Using ScrapeNinja lets you automate your web scraping and focus on the actual work of extracting useful information from the data. Check the ScrapeNinja site for details or to sign up.
Published on June 11, 2024
Related Questions
Tool Suggestions
Analyzing ScrapeNinja...