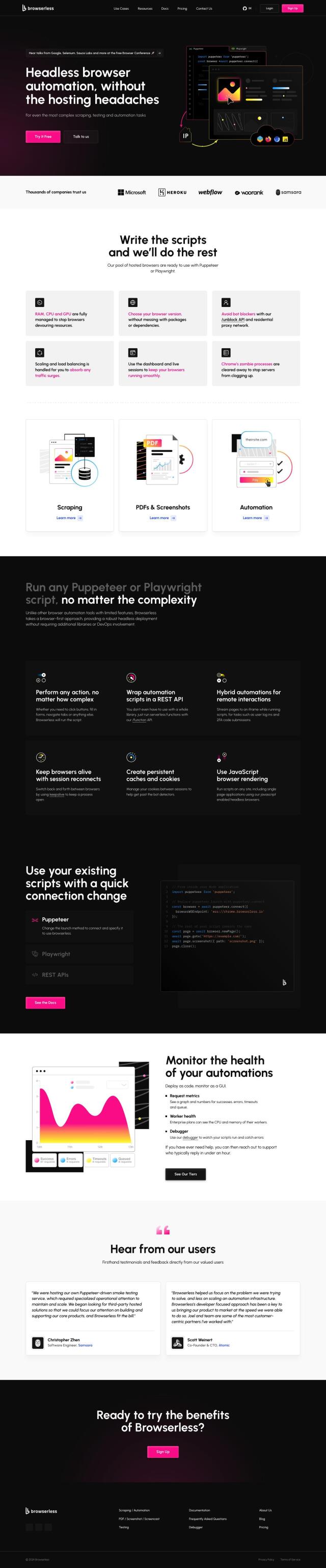
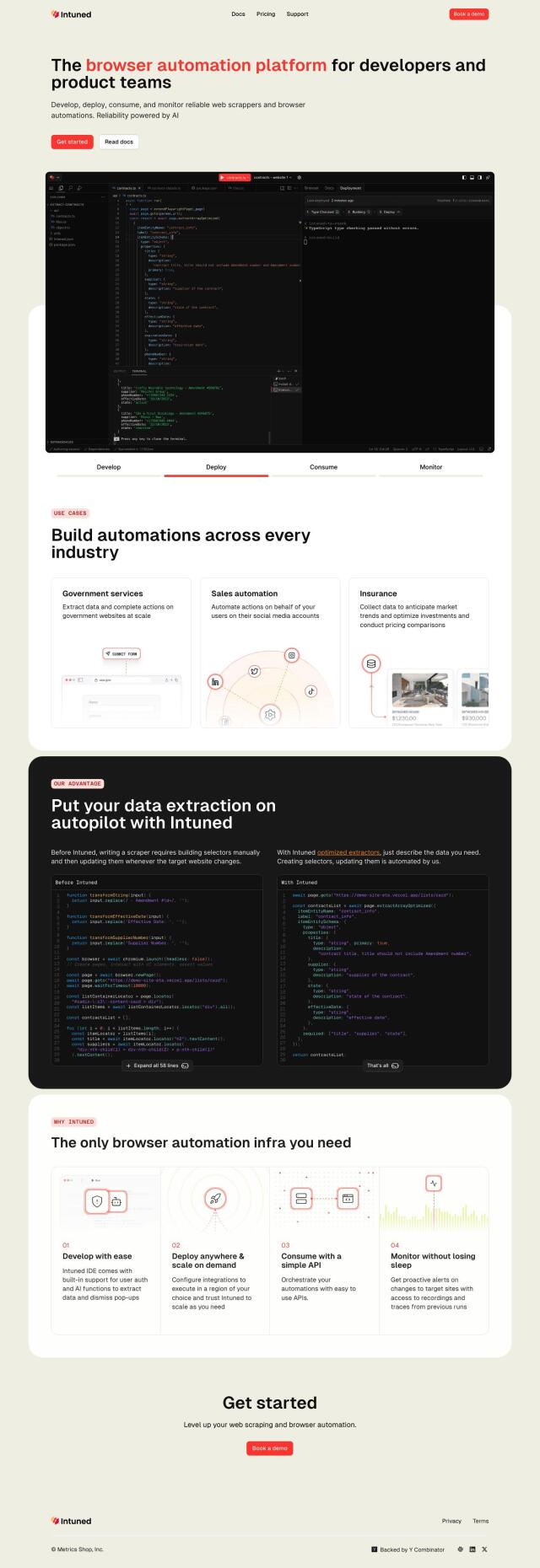
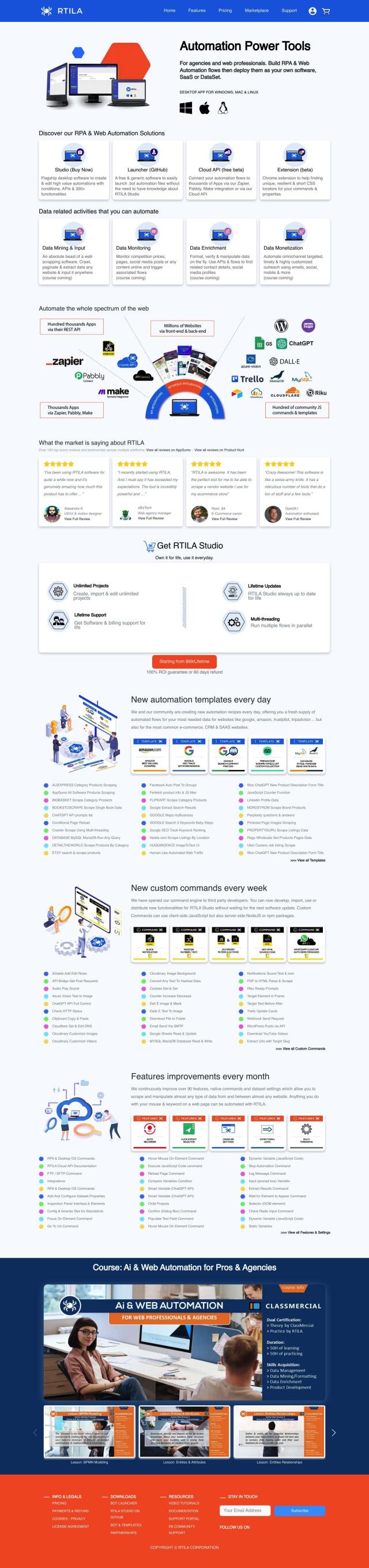
Question: How can I automate web scraping tasks to avoid IP blocking and timeouts?
ScrapeStorm
If you want to automate web scraping jobs so you don't get blocked by IP addresses and wait for timeouts, ScrapeStorm is worth a look. It's got AI-based data extraction, automatic CAPTCHA recognition and IP Rotation to get around IP address blocking. It can schedule data extractions and export data in various formats, so it's good for personal and business use.

ScrapingBee
Another good option is ScrapingBee, a web scraping API that uses headless browsers and proxies to tackle more sophisticated web scraping jobs. It can handle websites heavy with JavaScript, and it's got geotargeting and rotating proxies to get around rate limits and IP address blocking. ScrapingBee also offers a no-code web scraping option through Make integration, so it's accessible to those who don't know how to program.
Zyte
For a more developer-centric service, Zyte offers an AI-powered service with smart proxies and browsers to handle the ban handling and IP address rotation. It offers managed data extraction and cloud hosting with elastic pricing, so it's good for businesses and developers who need high accuracy and performance for web data extraction.

Bright Data
Last, Bright Data offers a full-featured web data collection service with a large network of residential proxy IPs and tools to get around blocks and CAPTCHAs. It's got a dynamic browser with built-in unblocking and proxies, so you can scrape the web ethically while getting useful retail competitive intelligence.