Question: Is there a Python module that can help me with paraphrase mining, semantic search, and clustering of text inputs?
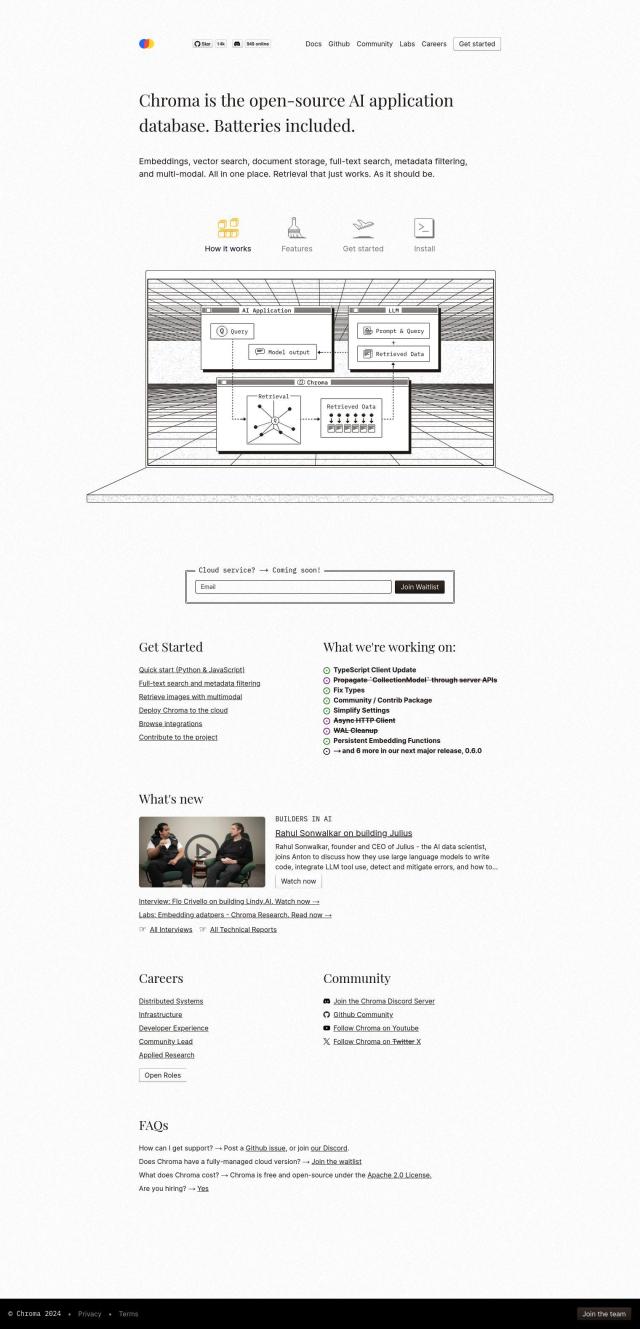
Sentence Transformers
If you want a one-stop shop for paraphrase mining, semantic search and text clustering, Sentence Transformers is a good option. This Python library includes state-of-the-art text and image embedding models that can be used for semantic search, semantic textual similarity, paraphrase mining and clustering. It includes more than 5,000 pre-trained models, and you can train or fine-tune your own models, too, so it's a good option for natural language processing chores.

Jina
Another interesting project is Jina, an AI information retrieval system that includes a range of tools to improve search, in particular for multimodal data. Jina includes multimodal and bilingual embeddings, rerankers, LLM-readers and prompt optimizers, and supports more than 100 languages. It also offers auto fine-tuning for embeddings, so it's a good option for situations where you need to search and retrieve data efficiently and accurately.
spaCy
For serious NLP work, spaCy is a free, open-source Python library that supports more than 75 languages and that offers features like named entity recognition, part-of-speech tagging, dependency parsing and word vector computation. spaCy's design is centered on a lightweight API, making it a good option for large-scale information extraction jobs. It also can be used with custom models built with PyTorch and TensorFlow.


deepset
And deepset offers a cloud platform and open-source Haystack framework for training and deploying large language models. The platform is geared for fast prototyping, model optimization and deployment, and can be used for a variety of tasks like retrieval augmented generation, conversational BI and vector-based search. It comes with pre-built templates and tools to make it easier to build and deploy custom LLM applications.