Question: Is there a platform that provides benchmarks and analytics for large language models, so I can evaluate their performance?
LLM Explorer
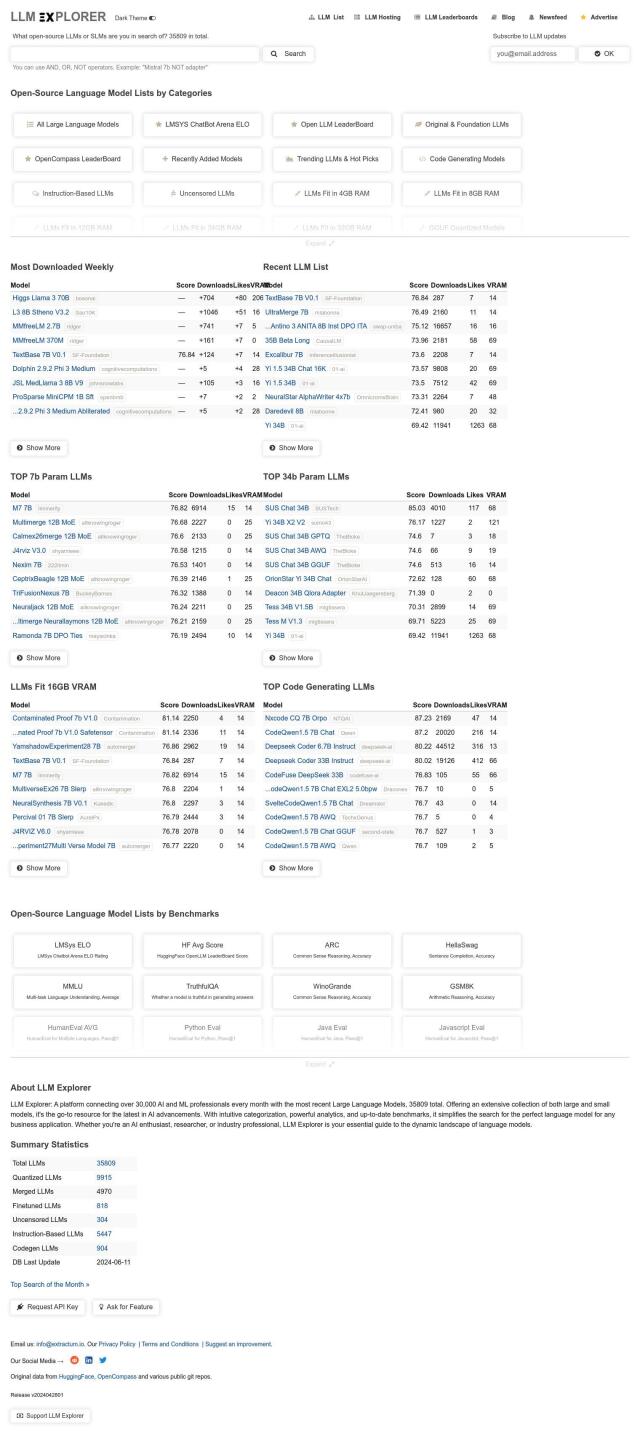
If you're looking for a platform that offers benchmarks and analytics for large language models, LLM Explorer is a great option. This one-stop-shop has a library of more than 35,000 open-source LLMs and SLMs that can be filtered by parameters like size, benchmark scores, and memory usage. It includes categorized lists, benchmarks, analytics and detailed model information, so you can easily explore and compare models. The platform is geared to help AI enthusiasts, researchers and industry professionals quickly find the right language models for their needs.

Langfuse
Another interesting platform is Langfuse, an open-source tool for debugging, analysis and iteration of LLM applications. It offers features like tracing, prompt management, evaluation, analytics and a playground for experimentation. Langfuse captures full context information of LLM executions and offers insights into metrics like cost, latency and quality. It supports integrations with multiple SDKs and offers different pricing tiers, so it can be used at different levels.

HoneyHive
For teams developing GenAI applications, HoneyHive is a full evaluation, testing and observability platform. It offers a single LLMOps environment for collaboration, testing and evaluation, along with automated CI testing, observability with production pipeline monitoring and dataset curation. HoneyHive supports use cases like debugging, online evaluation, user feedback and data analysis, so it's great for teams that need more advanced AI evaluation and monitoring tools.


Airtrain AI
Last, Airtrain AI is a no-code compute platform that also includes tools to handle big language models. It includes an LLM Playground for experimentation with more than 27 models, a Dataset Explorer for data visualization, and AI Scoring for evaluating models based on custom task descriptions. The platform is designed to make LLMs more accessible and economical, so you can quickly evaluate, fine-tune and deploy custom AI models.