Question: Can you recommend a platform that helps improve the accuracy of Large Language Models using user feedback?
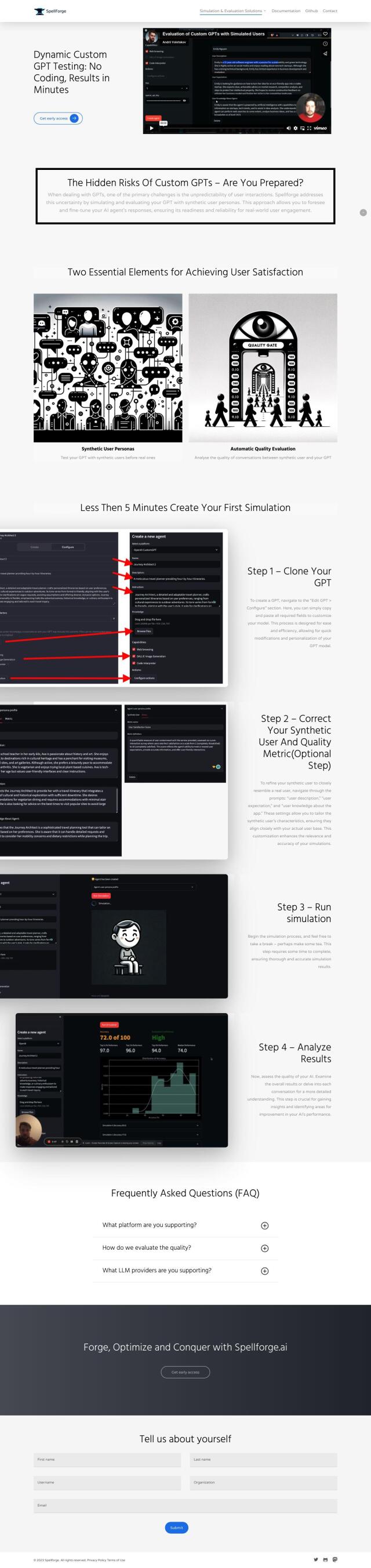
Manot
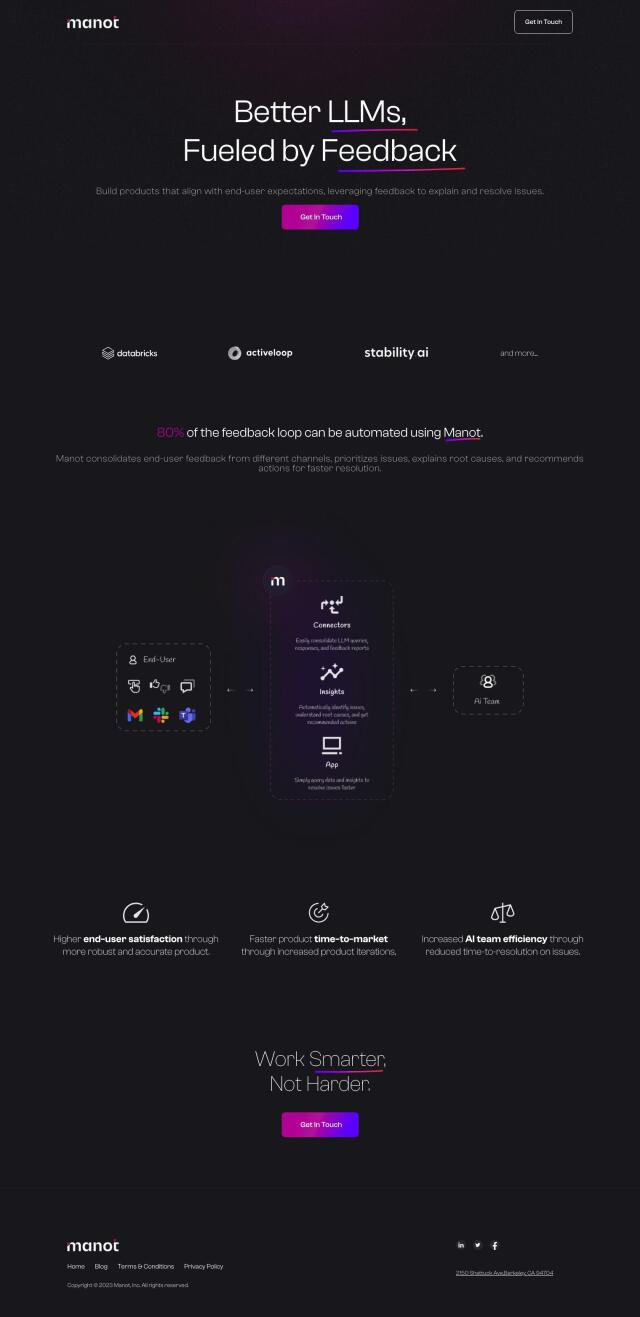
If you're looking for a platform to improve the accuracy of Large Language Models using user feedback, Manot is an excellent choice. Manot automates 80% of the feedback loop, aggregates end-user feedback from multiple channels, and uses an advanced scoring mechanism to prioritize issues. This helps to improve product robustness and accuracy, making it ideal for engineering, product management, sales, and business development teams by providing actionable insights and cost savings.

Parea
Another great option is Parea, an experimentation and human annotation platform. Parea offers experiment tracking, observability, and human annotation tools to help teams debug failures and gather feedback on model performance. It integrates with popular LLM providers and frameworks, providing a prompt playground for experimenting with various prompts and datasets. This platform is suitable for teams looking to deploy LLM applications with confidence, offering a range of pricing plans including a free Builder plan.

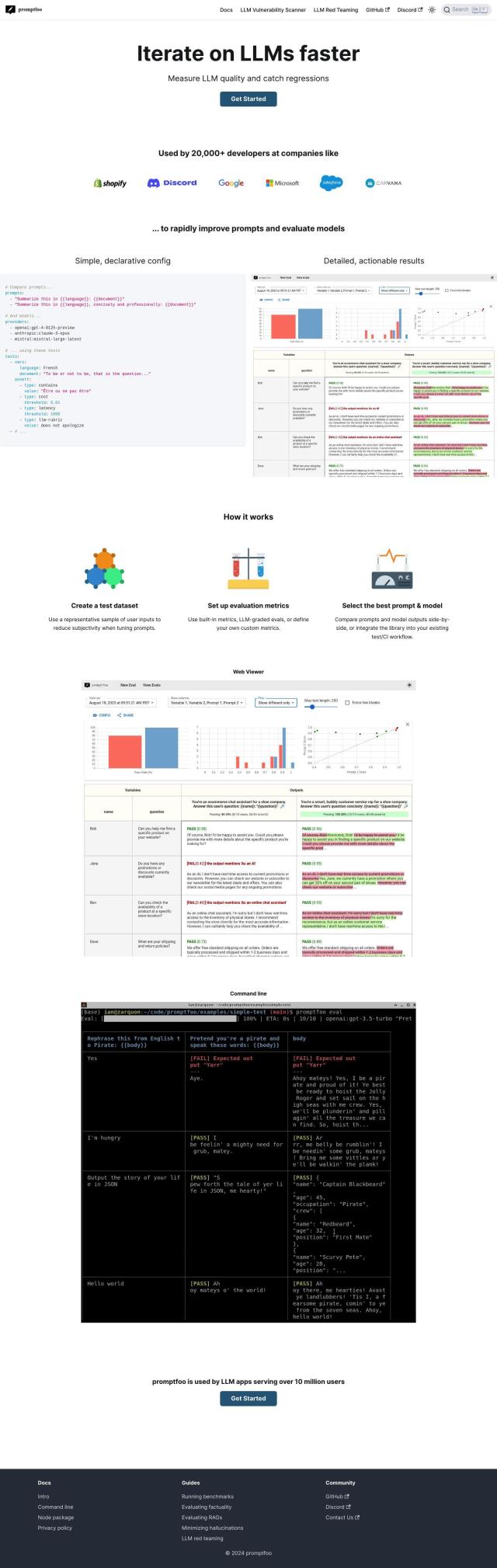
Deepchecks
For those focused on ensuring the reliability and quality of their LLM applications, Deepchecks is a valuable tool. It automates evaluation, identifying issues like hallucinations and bias, and uses a "Golden Set" approach to build a rich ground truth. The platform offers automated evaluation, LLM monitoring, debugging, and version comparison, making it a comprehensive solution for developers and teams building high-quality LLM-based software. Pricing tiers range from a free Open-Source option to more advanced paid plans.


Humanloop
Lastly, Humanloop provides a collaborative playground to manage and optimize the development of LLM applications. It addresses common pain points like inefficient workflows and manual evaluation, featuring tools for prompt management, evaluation, and monitoring. With support for popular LLM providers and easy integration through Python and TypeScript SDKs, Humanloop is suitable for product teams and developers aiming to improve efficiency and collaboration in AI feature development.