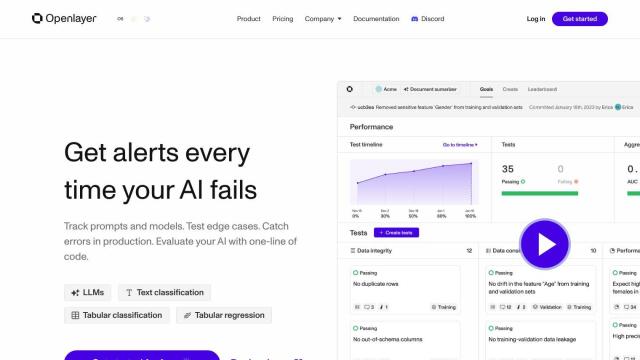
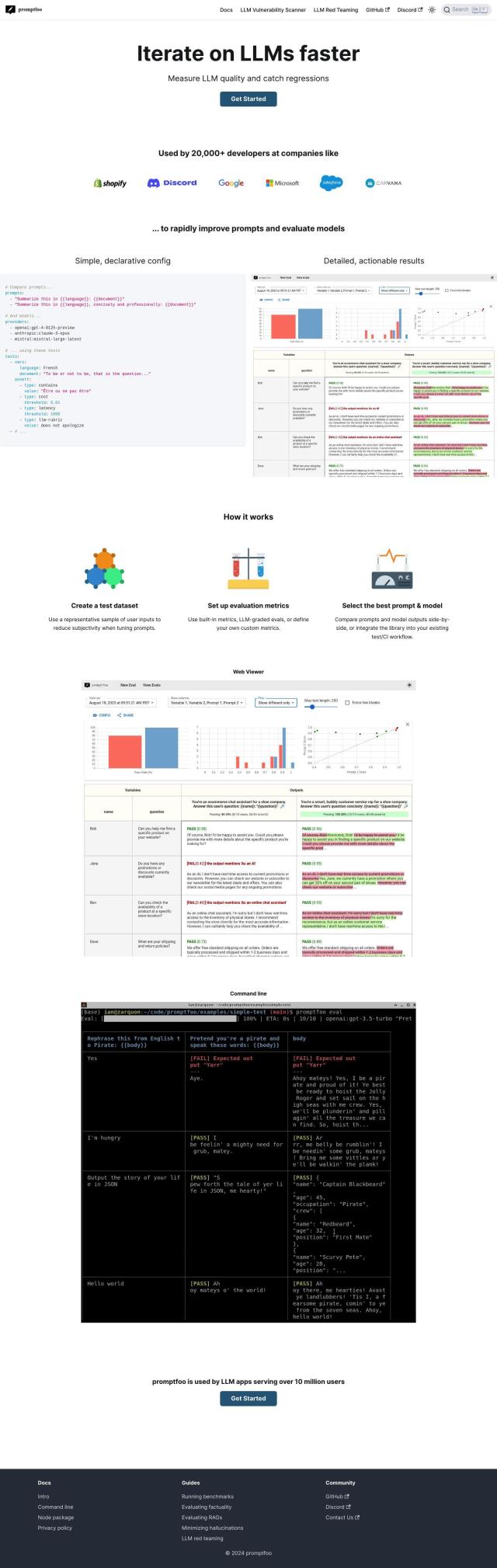
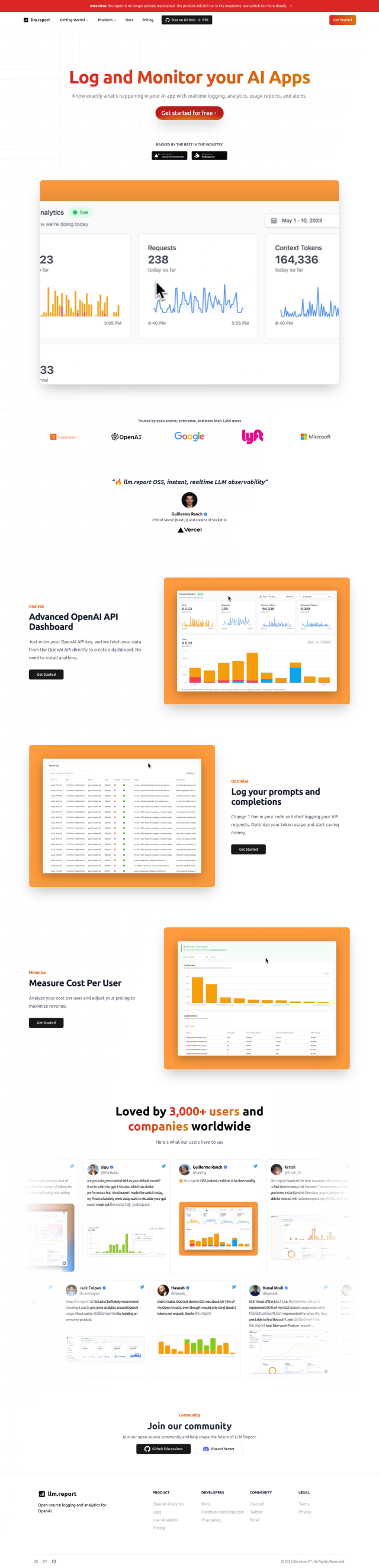
Question: How can I ensure my LLM model is performing consistently in production, is there a tool for that?

HoneyHive
To ensure your LLM model is running reliably in production, you might want to check out HoneyHive. This environment for testing, monitoring and evaluating LLMs includes features like automated CI testing, production pipeline monitoring, dataset curation, prompt management, and distributed tracing with OpenTelemetry. HoneyHive can be used for a variety of use cases, including debugging, online evaluation and user feedback, and offers free and enterprise options.

Langtail
Another good option is Langtail. Langtail is designed to make it easier to develop and deploy AI-powered apps with tools for debugging, testing and monitoring LLM prompts. It comes with a no-code playground for writing and running prompts, parameter tuning, test suites and logging. Langtail also offers rich metrics and problem detection to help you monitor production and avoid surprises. The service is available in free, Pro and Enterprise tiers.

Deepchecks
Deepchecks is another option. This tool lets developers create LLM apps more quickly with high quality by automating evaluation and flagging problems like hallucinations, bias and toxic content. Deepchecks uses a "Golden Set" approach that combines automated annotation with manual overrides for a richer ground truth for your LLM apps. It offers a variety of pricing options, including free and open-source versions, so it should be useful regardless of your level of sophistication.

Parea
Finally, Parea offers a range of tools to help AI teams ship LLM apps with confidence. It includes experiment tracking, observability and human annotation tools to debug failures, monitor performance and gather feedback. Parea also offers a prompt playground for trying out prompts and deploying into production. With integrations with popular LLM providers and frameworks, Parea can help you ensure reliable and high-quality model performance with various pricing plans to fit different needs.