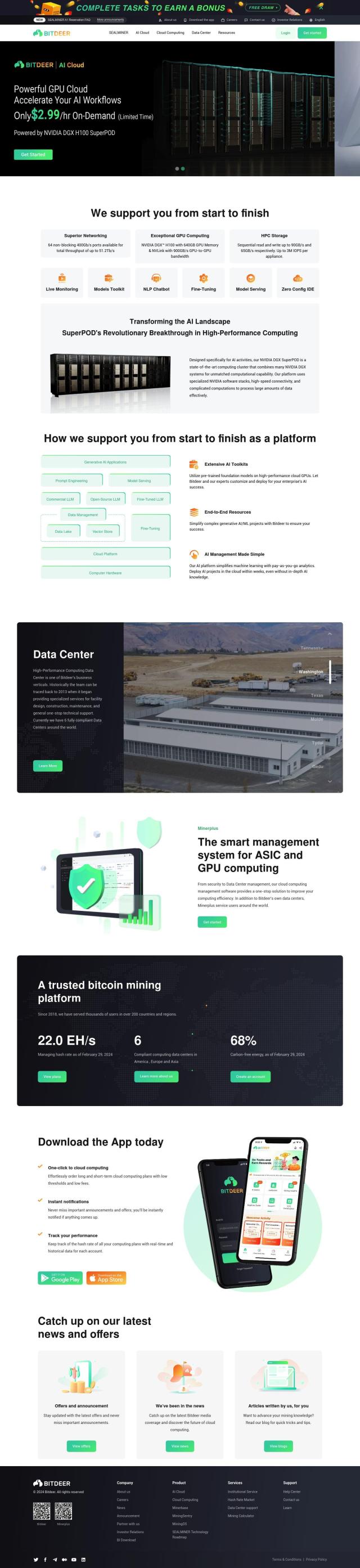
Question: I'm looking for a solution that allows me to quickly deploy GPU instances for machine learning and data analytics.
Lambda
If you need a service to spin up GPU instances for machine learning and data analysis work, Lambda is a good option. You can provision on-demand and reserved NVIDIA GPU instances and clusters for training and inferencing AI. With support for multiple NVIDIA GPUs and preconfigured ML environments, Lambda offers scalable file systems and one-click Jupyter access, so you can easily manage your GPU instances.


RunPod
Another good option is RunPod, a cloud service for developing, training and running AI models. It spins up GPU instances immediately and supports a range of GPUs. RunPod offers serverless ML inference, autoscaling and instant hot-reloading for local changes, as well as support for more than 50 preconfigured templates. It's competitively priced with a per-minute billing system, so you can pay only for what you use.


Cerebrium
If you want a serverless GPU foundation, check out Cerebrium. The service is billed on usage, which can be a big cost savings compared to more traditional approaches. Cerebrium supports multiple GPUs and offers features like hot reload, streaming endpoints and real-time logging. It also can be used in conjunction with AWS/GCP credits or on-premise infrastructure, so it should be adaptable to your needs.


Mystic
Last, Mystic offers a low-cost, scalable way to deploy and scale Machine Learning models with serverless GPU inference. It can be used on major cloud services like AWS, Azure and GCP, and offers features like spot instances and parallelized GPU usage for cost optimization. Mystic is designed to let data scientists focus on model development, not infrastructure.