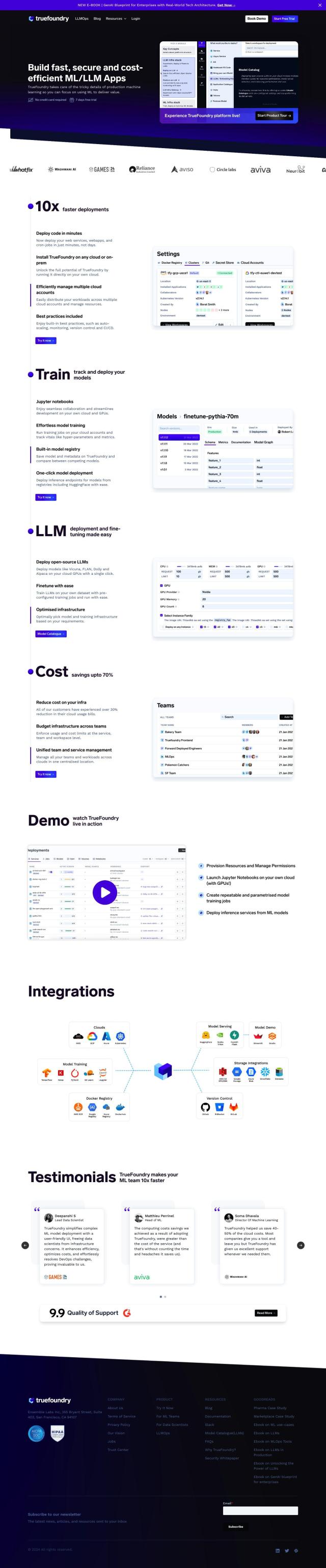
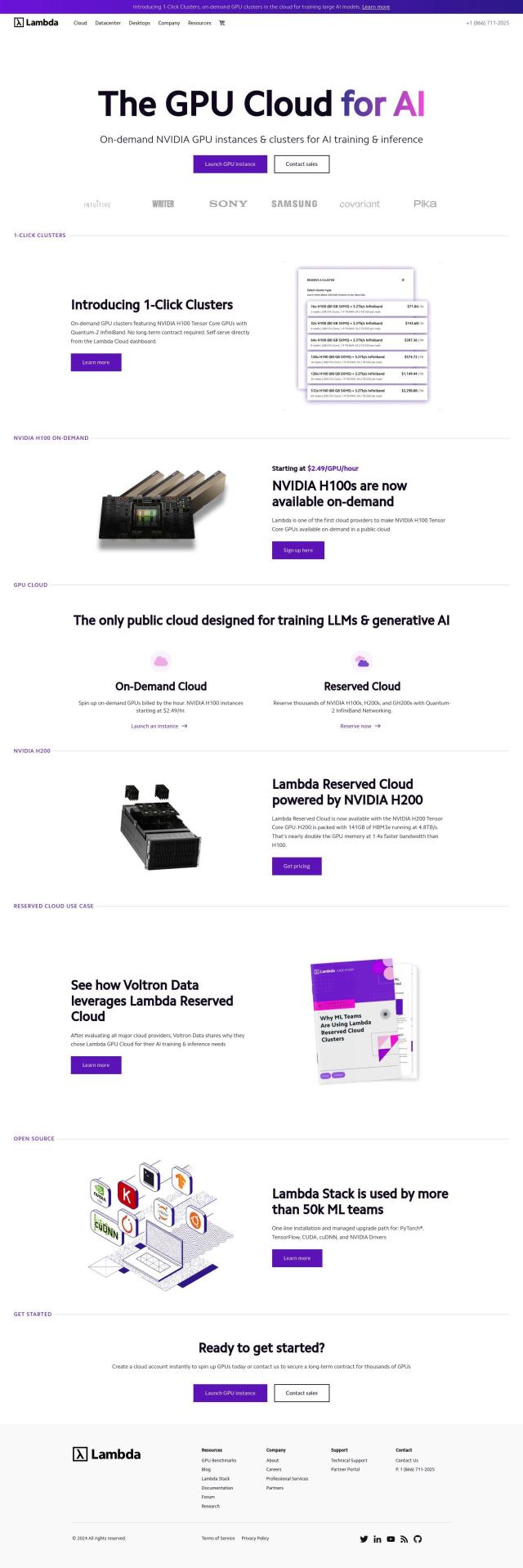
Question: I'm looking for a cost-effective way to serve and deploy large language models, do you know of any solutions?


Predibase
If you need a low-cost way to host and deploy large language models, Predibase is a good option. The service lets developers fine-tune and deploy LLMs, with free serverless inference up to 1 million tokens per day and a pay-as-you-go pricing model. It supports several models, including Llama-2, Mistral and Zephyr, and has enterprise-level security and dedicated deployment options.


Salad
Another good option is Salad, a cloud-based service that deploys and manages AI/ML production models at scale. Salad provides a low-cost way to tap into thousands of consumer GPUs around the world, with features including a fully-managed container service, global edge network, on-demand elasticity and multi-cloud support. Pricing starts at $0.02/hour for GTX 1650 GPUs, with deeper discounts for large-scale usage.


Together
Together is another option. The service accelerates AI model training and inference with techniques like Cocktail SGD and FlashAttention 2. It supports several models, has scalable inference, collaborative tools for fine-tuning and custom pricing for enterprise customers, and says it can save customers up to 50% compared with AWS and other suppliers.