Question: I need a tool to automate the testing and evaluation of my large language model app to ensure it's reliable and high-quality.

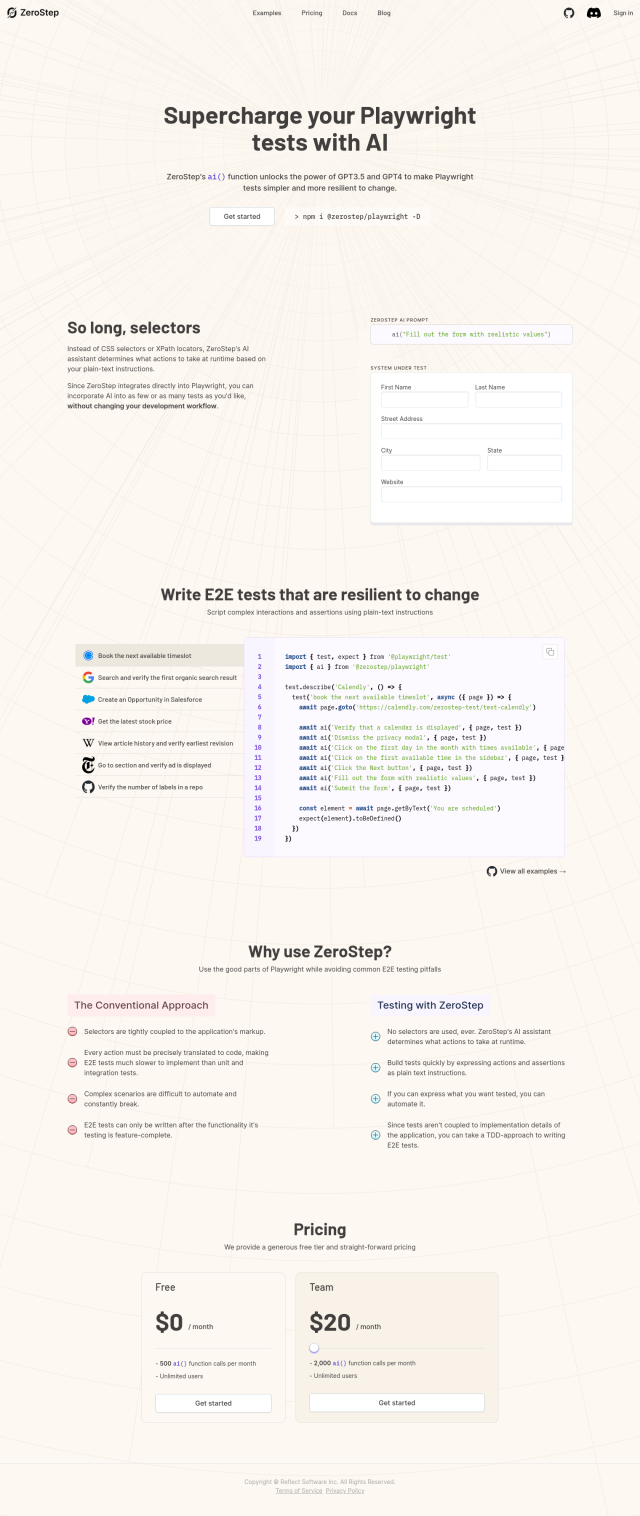
Deepchecks
If you want to automate testing and evaluation of your large language model app, Deepchecks is a wide-ranging tool designed to help developers guarantee the reliability and quality of their LLM applications. It evaluates your LLMs automatically, flagging issues like hallucinations, incorrect answers, bias and toxic content. Deepchecks' "Golden Set" approach combines automated annotation and manual overrides to create a rich ground truth, which makes it easier to ensure quality from development to deployment.
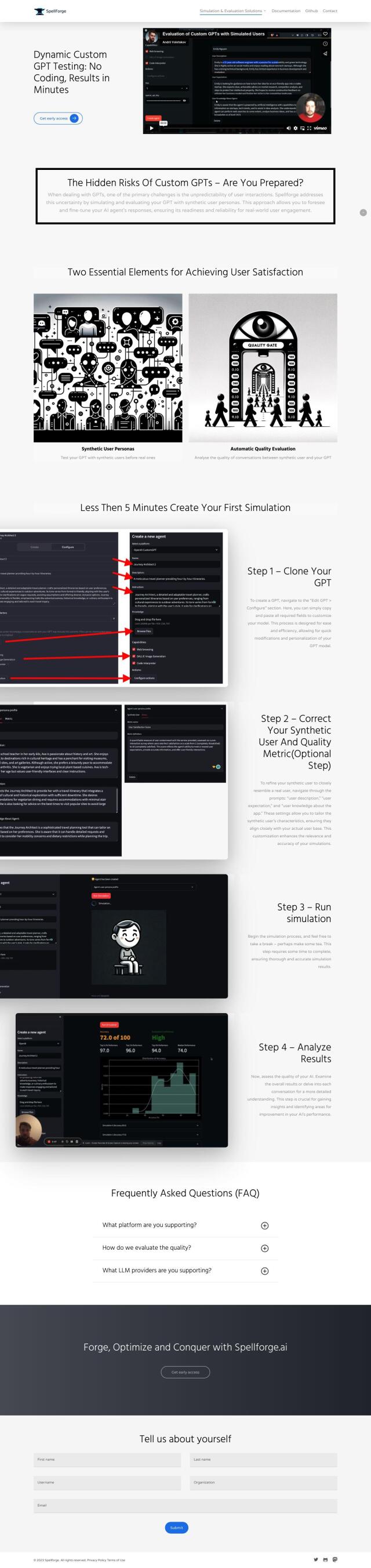
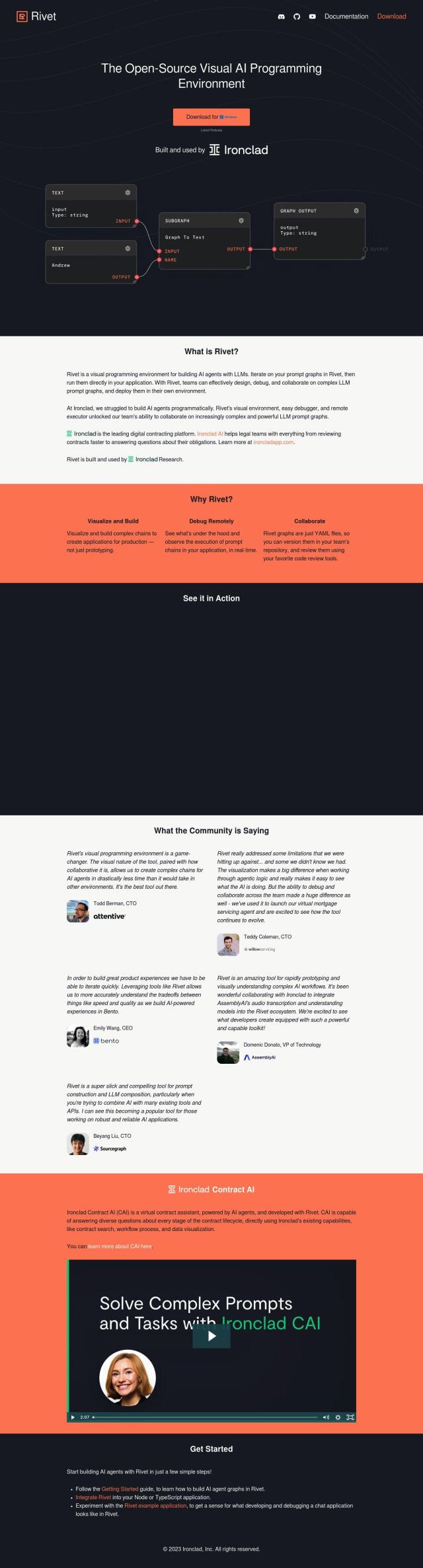
Spellforge
Another good choice is Spellforge, which serves as an AI quality gatekeeper by running simulations and tests within your existing release pipelines to ensure your LLMs are safe for use in the real world. It uses synthetic user personas to test and train AI agent responses, providing automated quality scoring and integration with your app or REST APIs. The tool is designed to minimize costs by optimizing LLM usage and supporting a range of use cases, including custom GPT models and ML models.

Langtail
For a more manual approach, Langtail offers a collection of tools for debugging, testing and deploying LLM prompts. It includes abilities like fine-tuning prompts, running tests to avoid unexpected behavior, and monitoring production performance with rich metrics. Langtail also offers a no-code playground for writing and running prompts, so teams can collaborate and build more reliable AI products.

LangWatch
Last, you might want to check out LangWatch, which helps you ensure the quality and safety of generative AI solutions by reducing risks like jailbreaking and sensitive data exposure. It offers real-time metrics for conversion rates, output quality and user feedback, and tools to create test datasets and run simulation experiments. LangWatch is geared for developers and product managers who need to ensure high quality and performance in their AI applications.