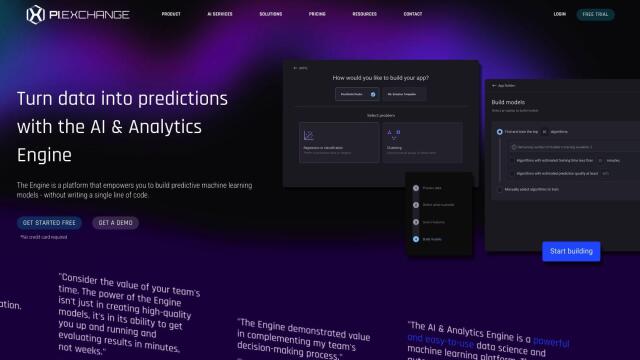
GPUDeploy Alternatives



RunPod
If you're looking for a GPUDeploy alternative, RunPod is a good option. It's a globally distributed GPU cloud that lets you run any GPU workload with a single command to spin up GPU pods. The service supports a range of GPUs and charges by the minute with no egress or ingress fees. It also has features like serverless ML inference, autoscaling and job queuing, so it's good for developers and researchers who need flexibility.


Anyscale
Another option is Anyscale, which is geared for developing, deploying and scaling AI applications. It's got workload scheduling, cloud flexibility spanning multiple clouds and on-premise environments, and smart instance management. Anyscale also supports a range of AI models and has native integration with popular IDEs, so it's a powerful foundation for optimized resource utilization and cost optimization.


Salad
If you're on a budget, check out Salad. It's a cloud-based service for deploying and managing AI/ML production models at scale, using thousands of consumer GPUs around the world. Salad has scalability, a fully-managed container service and a global edge network, with costs up to 90% lower than traditional providers. It supports a range of GPU-hungry workloads and integrates with popular container registries.


Cerebrium
Last, Cerebrium is a serverless GPU infrastructure for training and deploying machine learning models at a lower cost. With features like 3.4s cold starts, high scalability and real-time monitoring, Cerebrium is geared for ease of use and high performance. It supports GPU variety, infrastructure as code and real-time logging and monitoring, so it's a good tool for ML model deployment and scaling.