Question: How can I run multiple AI models on a single server while maximizing resource utilization?


Anyscale
Anyscale is a full-stack platform for building, deploying and scaling AI workloads. It supports a variety of AI models and includes features like workload scheduling, heterogeneous node control and GPU and CPU fractioning to get the most out of your resources. Anyscale is based on the open-source Ray framework and includes native integrations with popular IDEs, persisted storage and Git integration, making it a powerful option for managing AI workloads at scale.
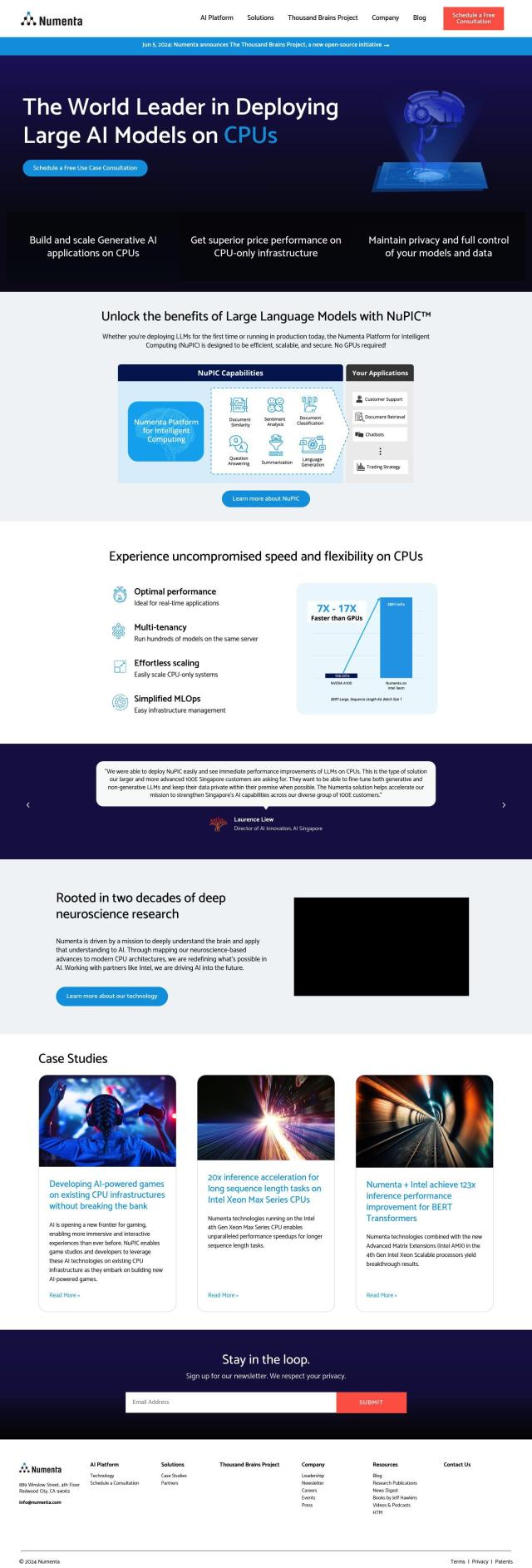
Numenta
Numenta is another good option, particularly for running big AI models on CPUs. It uses the NuPIC system for Generative AI workloads without GPUs, so it can be a good option for those who want to save money. Numenta offers real-time performance optimization, multi-tenancy for running hundreds of models on a single server, and MLOps to manage infrastructure. That makes it a good option for gaming and customer support.


RunPod
For a cloud-based option, RunPod is a globally distributed GPU cloud that lets you run any GPU workload. It offers instant spinning up of GPU pods, a range of GPUs and serverless ML inference with autoscaling and job queuing. RunPod also supports more than 50 preconfigured templates for frameworks like PyTorch and Tensorflow, and offers real-time logs and analytics for easy deployment and management of AI models.


dstack
Dstack is an open-source engine that automates infrastructure provisioning for the development, training and deployment of AI models on multiple cloud providers and data centers. It makes it easy to set up and run AI workloads, so you can concentrate on data and research instead of infrastructure. Dstack supports a range of cloud providers and on-prem servers, so it can be used in a variety of deployment scenarios.