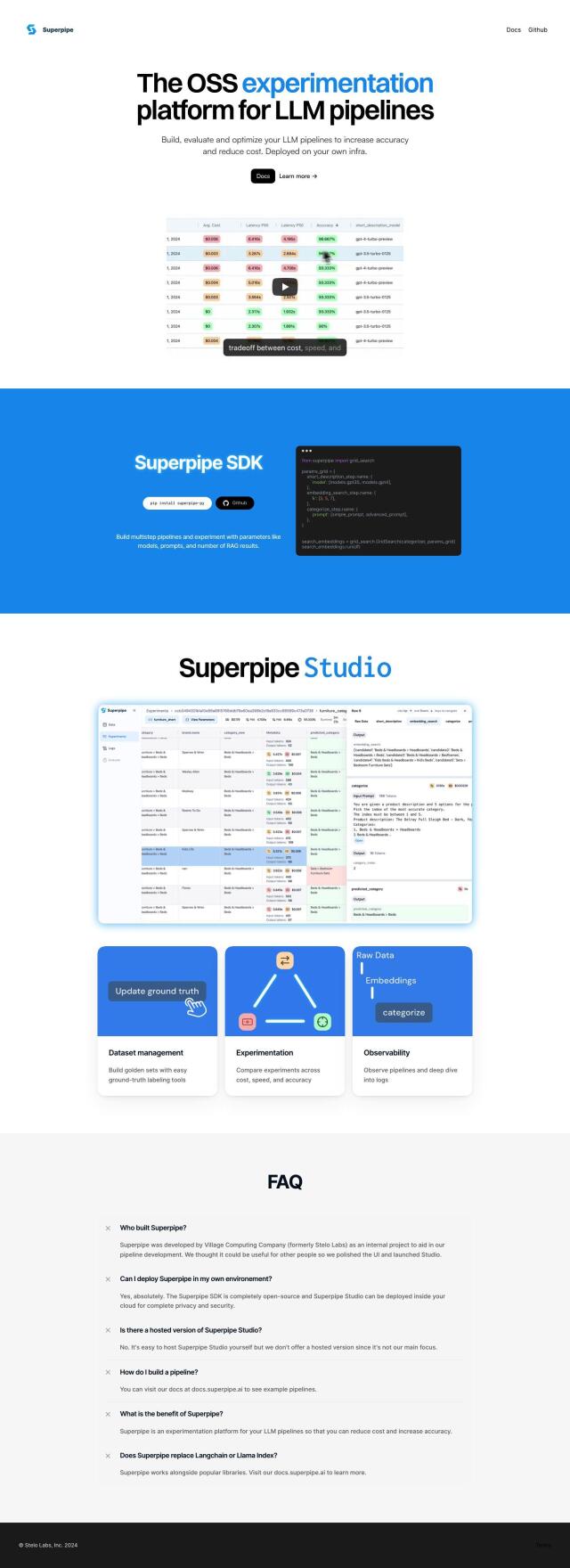
Question: Can you recommend a research organization that provides large-scale datasets for evaluating and developing large language models?


LMSYS Org
If you're looking for a research organization that offers large-scale datasets for training and testing large language models, LMSYS Org is definitely worth a look. LMSYS Org is working to democratize large model technology through open-source projects and has several projects related to LLMs, including Vicuna, Chatbot Arena, SGLang, and MT-Bench. On top of that, it offers large-scale datasets like LMSYS-Chat-1M and Chatbot Arena Conversations that can help you get large model tech up and running faster.

Gretel Navigator
Another interesting option is Gretel Navigator, which creates, edits and amplifies tabular data. That's useful for creating a dataset from scratch, and it's got tools like creating plausible data, data augmentation for ML training and creating evaluation datasets. Gretel Navigator is used by companies like Ernst & Young and Databricks to improve data quality and speed up product development.

SuperAnnotate
If you're looking for a more general-purpose platform that can handle a variety of AI tasks, SuperAnnotate is an end-to-end platform for training, testing and deploying LLMs and other AI models. It includes data ingestion, customizable UI, dataset creation, model testing and deployment to multiple environments. With data insights and analytics tools and a marketplace for vetted annotation teams, SuperAnnotate is designed to keep data private and secure while speeding up AI development.
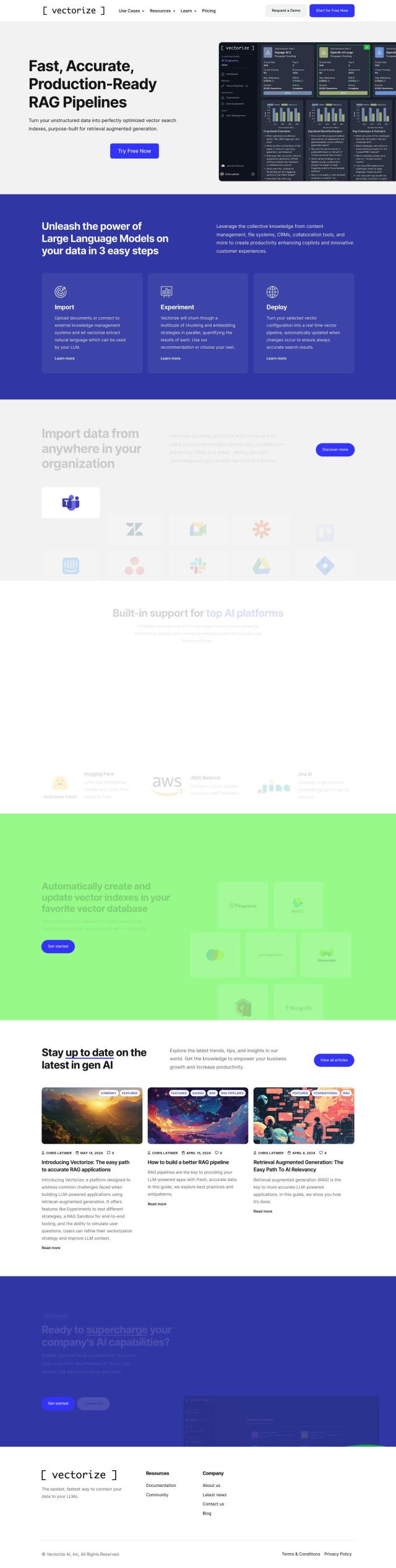
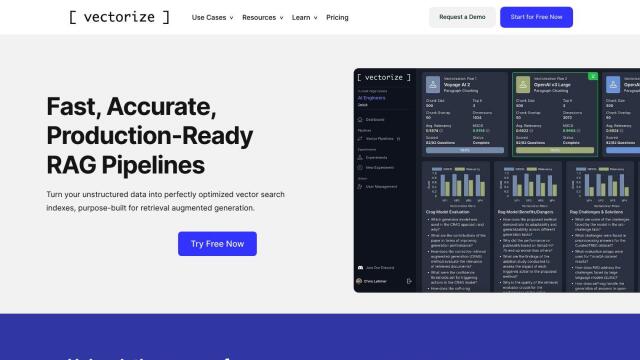
LlamaIndex
Last, LlamaIndex offers a data framework that combines custom data sources with large language models, supporting more than 160 data sources and multiple data formats. That's good for use cases like financial services analysis, advanced document intelligence and enterprise search. With a Python and TypeScript package, a wealth of community resources and a variety of service options, LlamaIndex can help you automate your LLM application workflows.