Question: Looking for a solution that provides instant hot-reloading for local changes, so I can test and deploy AI models without interruption.


RunPod
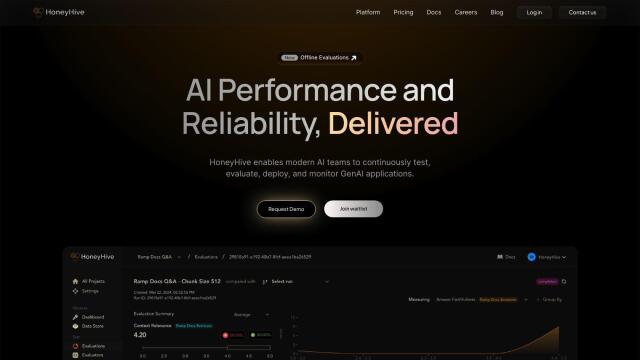
If you need a service that lets you hot-reload locally modified code without stopping your AI model for testing and deployment, RunPod is a good option. This cloud service for developing, training and running AI models lets you spin up GPU pods instantly and hot-reload instantly when you make changes locally. It comes with more than 50 preconfigured templates for frameworks like PyTorch and Tensorflow, and you can use a CLI tool to provision and deploy. The service also has 99.99% uptime, 10PB+ of network storage and real-time logs and analytics.


Cerebrium
Another option is Cerebrium, a serverless GPU infrastructure service that's designed to scale well with features like 3.4s cold starts, 5000 requests per second and 99.99% uptime. It also comes with infrastructure as code, volume storage, secrets, hot reload and streaming endpoints. Real-time logging and monitoring make it easier to debug and monitor performance. Cerebrium's pay-per-use pricing is a good option, with tiered plans for different needs.


Anyscale
If you want a more full-featured service, check out Anyscale. It's got workload scheduling with queues, cloud flexibility across multiple clouds and on-premise, and smart instance management. Anyscale supports a broad range of AI models and has native integrations with popular IDEs and persisted storage. The service also offers a free tier and flexible pricing plans with volume discounts for large enterprises.


dstack
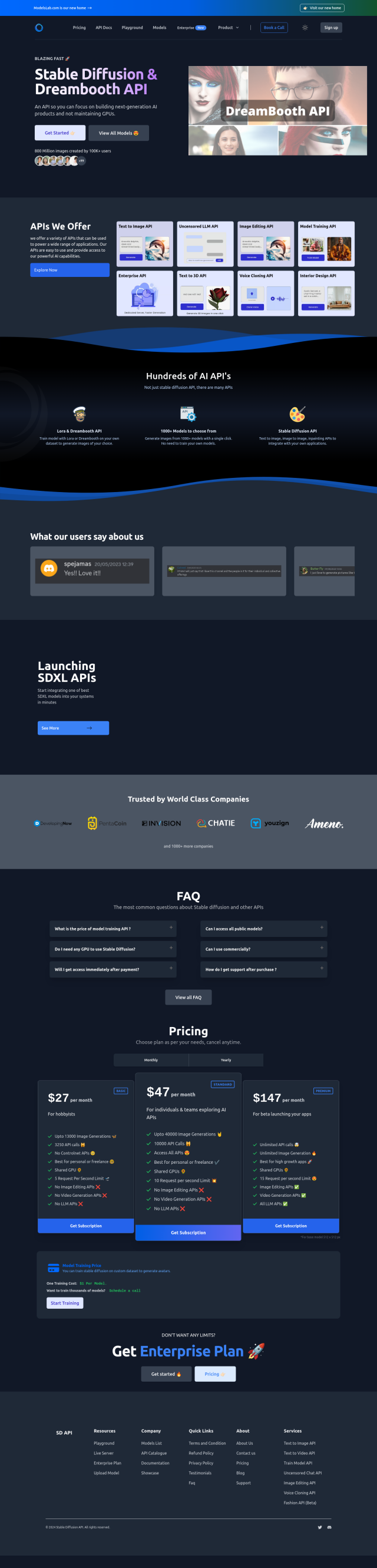
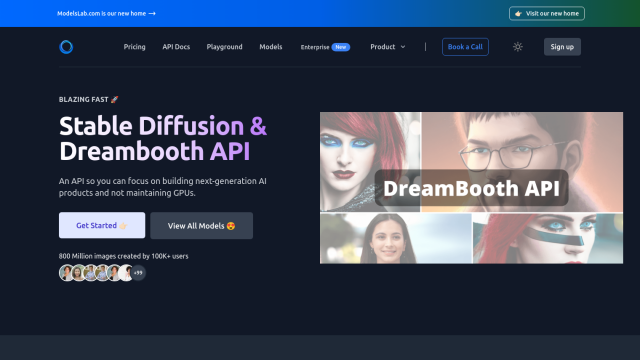
Last, dstack is an open-source engine that automates infrastructure provisioning for AI model development, training and deployment on a variety of cloud providers and data centers. It streamlines AI workload setup and execution so you can focus on data and research. dstack supports a variety of cloud providers and offers several deployment options, including open-source self-hosted and managed dstack Sky versions.