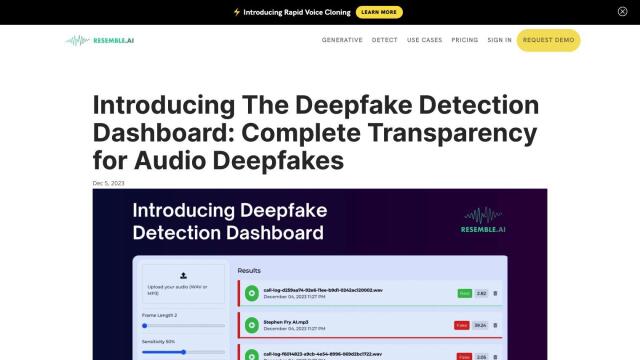
Question: Can you recommend a service that offers human-created datasets for speech recognition and sentiment analysis?

AssemblyAI
AssemblyAI has a broad range of AI models for speech-to-text transcription, sentiment analysis and other tasks. It's trained on 12.5 million hours of multilingual audio data and supports more than 99 languages. It's got features like streaming speech-to-text, speaker diarization and low-latency transcription. With integration tools that work in many programming languages and a variety of pricing plans, AssemblyAI is a good fit for companies building their own AI products that use voice data.

Appen
Another option is Appen, which offers high-quality, diverse datasets for AI training. Its reputation is built on human feedback and human-AI collaboration, but its platform can handle multiple data types, including audio, and is used by major companies. It's customizable, with workflows and built-in quality control, and can scale to accommodate large amounts of data for training and fine-tuning AI models.

Clickworker
If you want a more global approach, Clickworker taps into a global crowd of freelancers to create, validate and label high-quality AI training data. The service offers a range of data options, including audio and NLP, and focuses on quality and reliability with ISO 27001 certification and GDPR compliance. That makes it a good choice for companies that want to improve AI system performance with high-quality training data.