Question: I need a tool to evaluate the quality of my large language model output, can you suggest something?
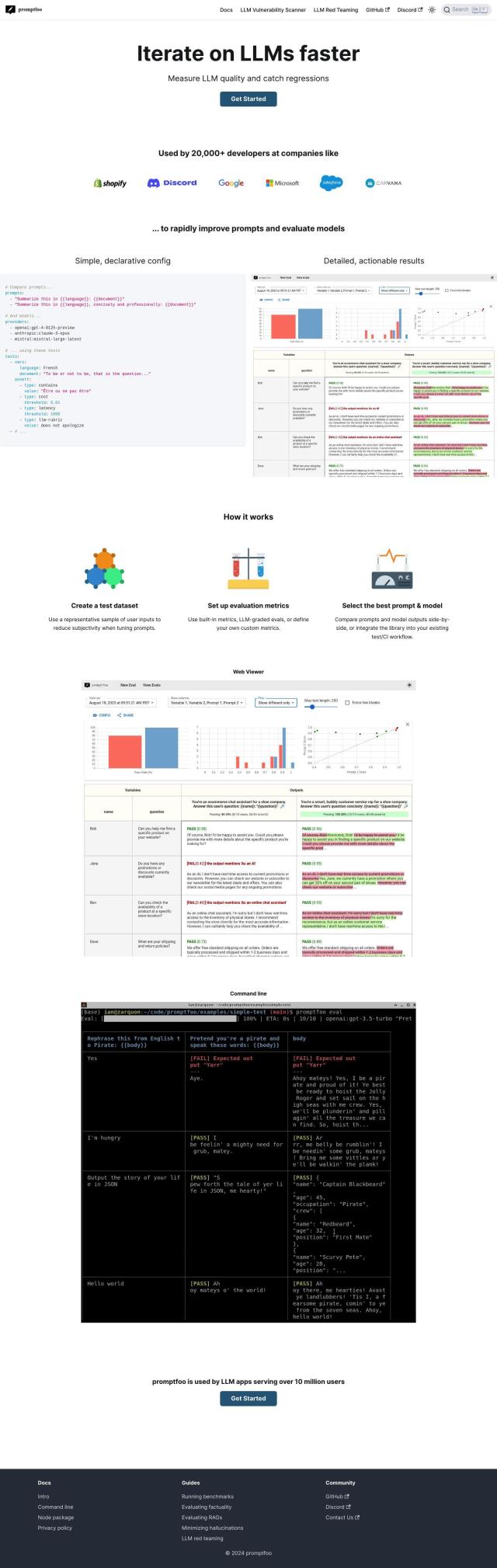
Promptfoo
If you're looking for a tool to evaluate the quality of your large language model output, Promptfoo is an excellent choice. It offers a command-line interface and a Node.js library for developers to optimize model quality and monitor for regressions. It supports multiple LLM providers and includes customizable evaluation metrics. Additionally, it features a red teaming component that generates custom attacks to find potential weaknesses, providing remediation advice for better model security.

Deepchecks
Another powerful tool is Deepchecks. This system automates the evaluation of LLM applications, identifying issues like hallucinations, wrong answers, bias, and toxic content. It uses a "Golden Set" approach for rich ground truth development and provides features for automated evaluation, LLM monitoring, and debugging. With multiple pricing tiers, Deepchecks is suitable for developers and teams looking to ensure high-quality LLM-based software from development to deployment.

LangWatch
For those specifically focused on safety and performance, LangWatch offers robust guardrails and real-time metrics to continuously optimize model quality and safety. It helps mitigate risks like jailbreaking and hallucinations, ensuring reliable and faithful AI responses. LangWatch is ideal for developers, product managers, and anyone involved in building AI applications that require high standards of quality and performance.
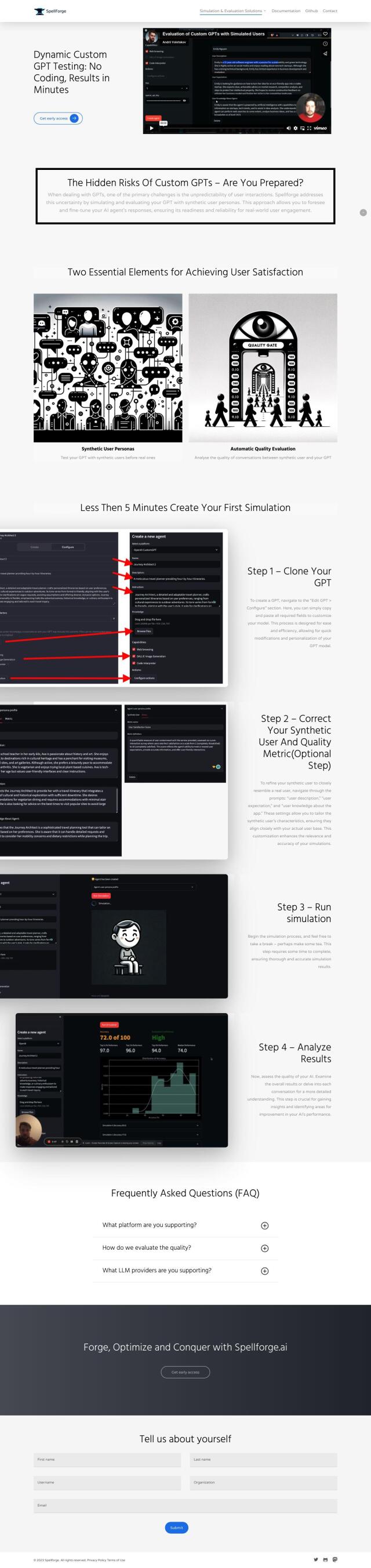
Spellforge
Spellforge is another noteworthy tool, designed to run simulations and tests on LLMs in existing pipelines to ensure reliability. It uses synthetic user personas to test AI agent responses and offers automatic quality assessment with easy integration into apps or REST APIs. This tool is particularly useful for integrating LLMs into Continuous Integration systems to provide high-quality AI interactions.