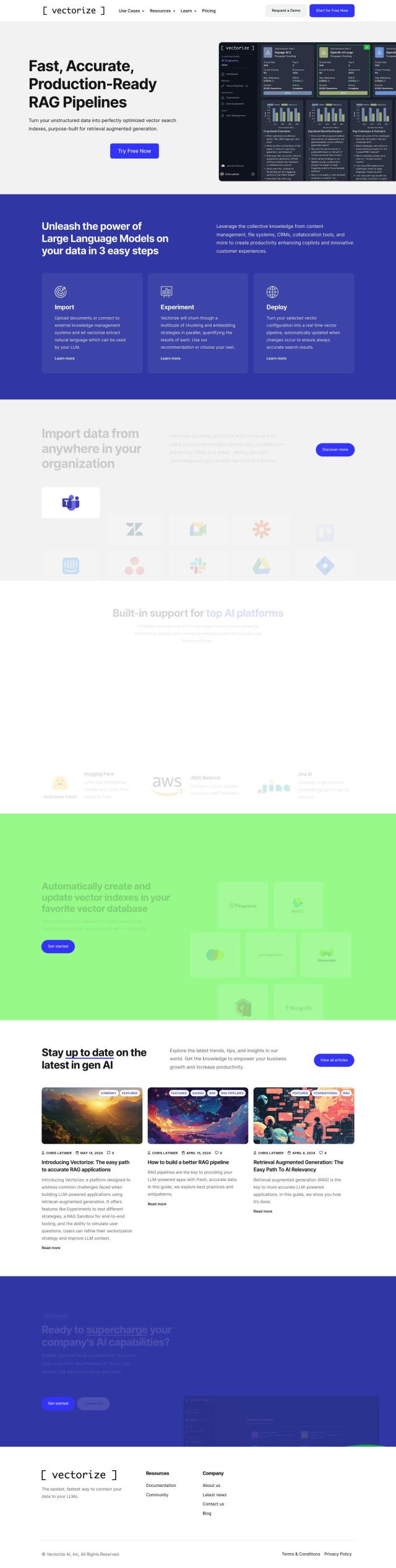
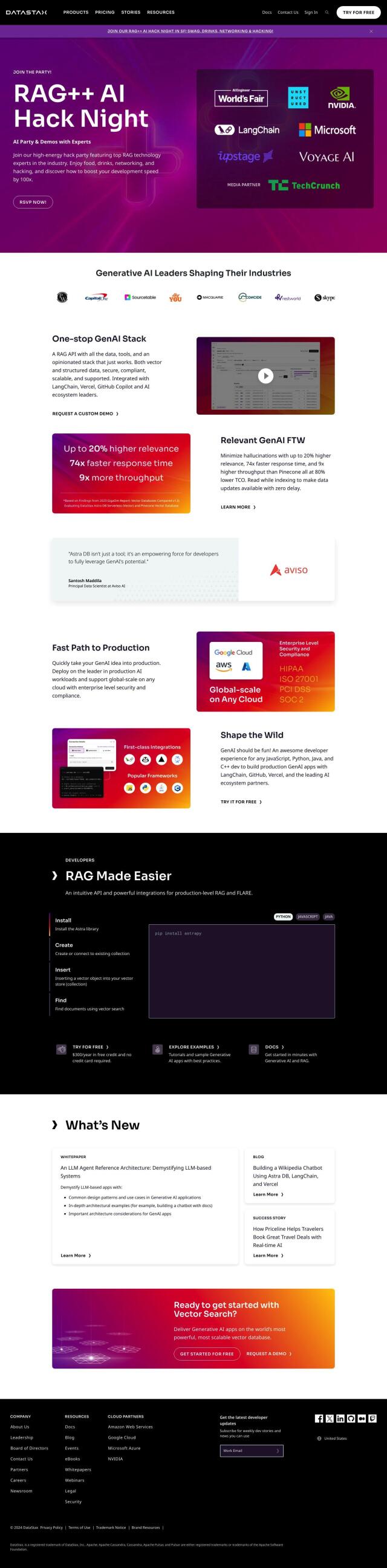
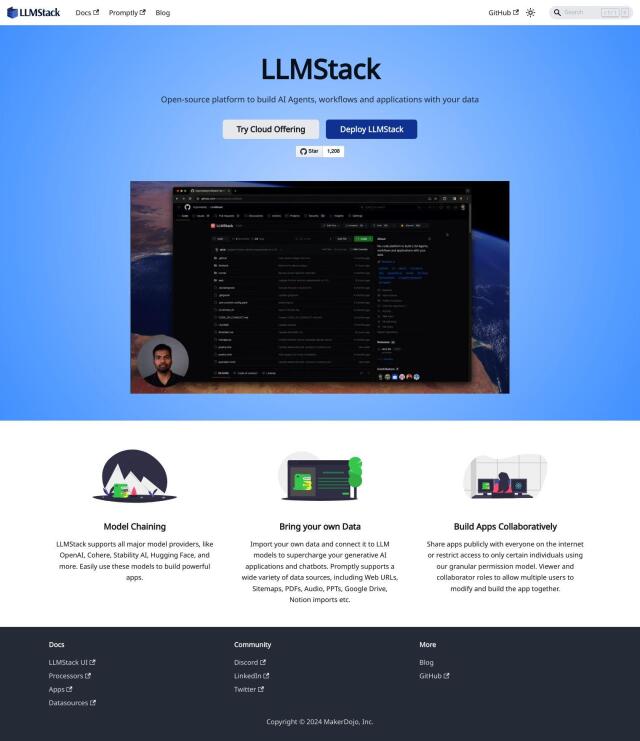
Question: How can I efficiently store and version different data types, such as documents and images, for my language model tasks?


Baseplate
If you need to store and version different data types like documents and images for your language model work, Baseplate is a good choice. It offers a data management system geared for Large Language Model (LLM) use. Baseplate combines different data types into a single hybrid database and offers vector database management with automatic versioning. That lets you build multimodal LLM responses and makes data management easier, so developers can concentrate on building useful AI apps.


Pinecone
Another good choice is Pinecone, a vector database geared for fast querying and retrieval of similar matches. Pinecone offers low-latency vector search, metadata filtering, real-time indexing, and hybrid search. It offers several pricing levels, including a free starter plan, and works with big cloud providers, so it's a good choice for large-scale, cost-effective use. The service is geared for high-performance retrieval workflows that are common with language model use.
SingleStore
SingleStore is another option. It's a real-time data platform that can handle petabyte-scale data sets and combines transactional and analytical data in one engine. It can deliver millisecond query performance and supports multiple data models, including JSON, time-series, vector and full-text search. SingleStore is geared for use in intelligent applications like generative AI and real-time analytics, with flexible scaling and high availability.
LlamaIndex
Last, LlamaIndex offers a broad data framework for connecting your own data sources to large language models. It supports more than 160 data sources and a range of vector, document, graph and SQL database suppliers. LlamaIndex handles data loading, indexing and querying for production LLM workflows, so it's a good choice if you want to bring your own data in different formats and structured data to your AI apps.