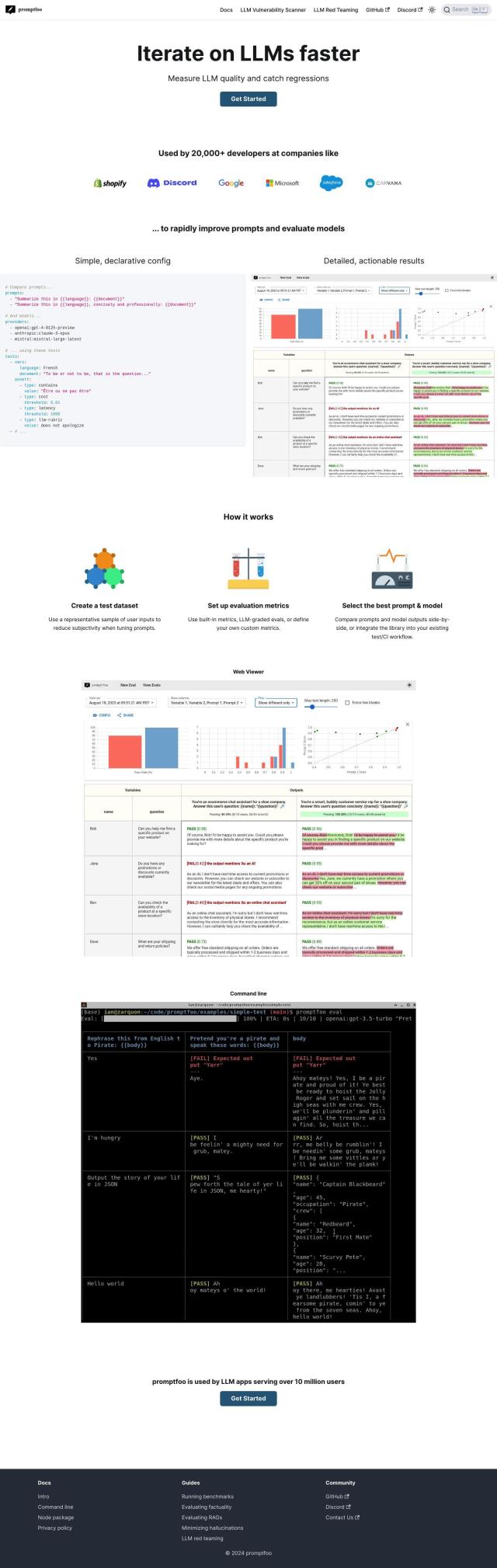
Question: I'm looking for a way to debug failures and gather human feedback on my model's performance, do you know of a solution?

Parea
Parea is an experimentation and human annotation platform geared for AI teams. It has a full suite of tools for experiment tracking, observability and human annotation that lets teams debug failures, track performance over time and get human feedback. Parea also has a prompt playground for testing different prompts and integrates with several LLM providers and frameworks like OpenAI and Anthropic.

HoneyHive
Another good option is HoneyHive, an AI evaluation, testing and observability platform. It has a single LLMOps environment for collaboration, testing and evaluation, which is useful for monitoring and debugging LLM failures in production. HoneyHive also includes tools for automated CI testing, observability, dataset curation, prompt management and human feedback collection, which can significantly improve the development and maintenance of your AI applications.


Humanloop
If you prefer a collaborative approach, Humanloop is a platform that manages and optimizes the development of Large Language Model applications. It includes a collaborative prompt management system, an evaluation and monitoring suite for debugging, and tools for connecting private data and fine-tuning models. Humanloop supports popular LLM providers and offers SDKs for easy integration, making it a good choice for product teams, developers and anyone building AI features.