Question: I'm struggling to debug my generative AI application, can you suggest a platform that helps with RAG pipeline optimization and hallucination detection?


LastMile AI
If you're having a hard time debugging your generative AI program, LastMile AI could be a good option. The service is geared to let engineers productionize generative AI programs with confidence. It includes features like Auto-Eval to detect hallucinations automatically, RAG Debugger to optimize performance, Consult AI Expert for help from a team of engineers and ML researchers, and AIConfig to tune prompts and model parameters. It also supports multiple AI models and comes with a prototyping and app-building environment so you can more easily deploy production-ready AI apps.

HoneyHive
Another good option is HoneyHive, which offers a full-featured AI evaluation, testing and observability service. It includes a single LLMOps environment for collaboration, testing and evaluation, along with automated CI testing, observability and prompt management. HoneyHive also offers support for 100+ models through integrations with common GPU clouds and offers different pricing tiers, including a free developer plan and a customizable enterprise plan.

Deepchecks
If you're looking for something more specialized for monitoring and correcting LLMs, Deepchecks offers a mature platform to automate evaluation and catch problems like hallucinations and bias. Its "Golden Set" approach combines automated annotation with manual overrides to create a rich ground truth for LLM applications. It's particularly useful for ensuring the reliability and high quality of LLM-based software from development to deployment.
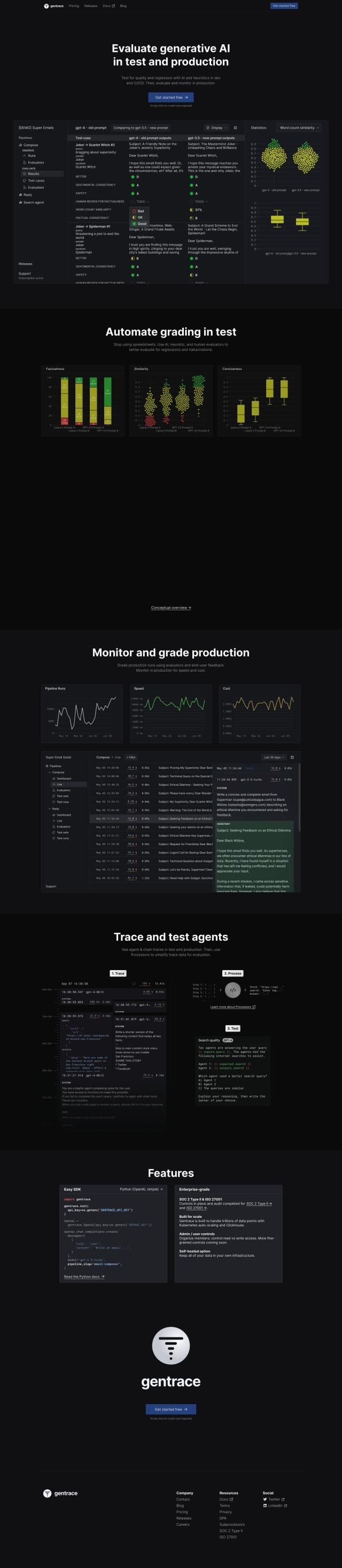
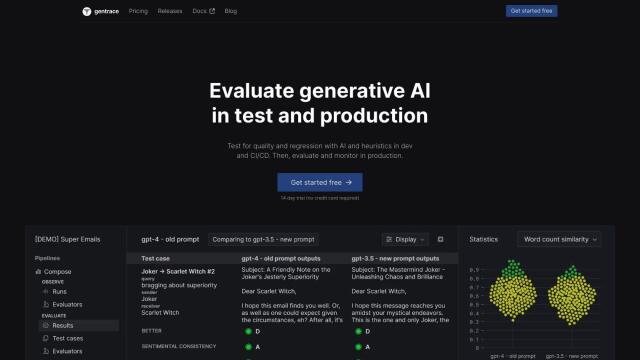
Gentrace
Last, Gentrace offers an AI-powered system to assess and monitor generative AI quality in both test and production environments. It includes features like automated grading, factualness assessment and pipeline runs monitoring. Gentrace can be used to evaluate user queries and monitor production runs, and it offers flexible pricing options and detailed documentation to help you integrate it into your workflow.