Question: Is there a data repository that offers cleaned and preprocessed data sets for use in scientific research and policy-making?
Data Commons
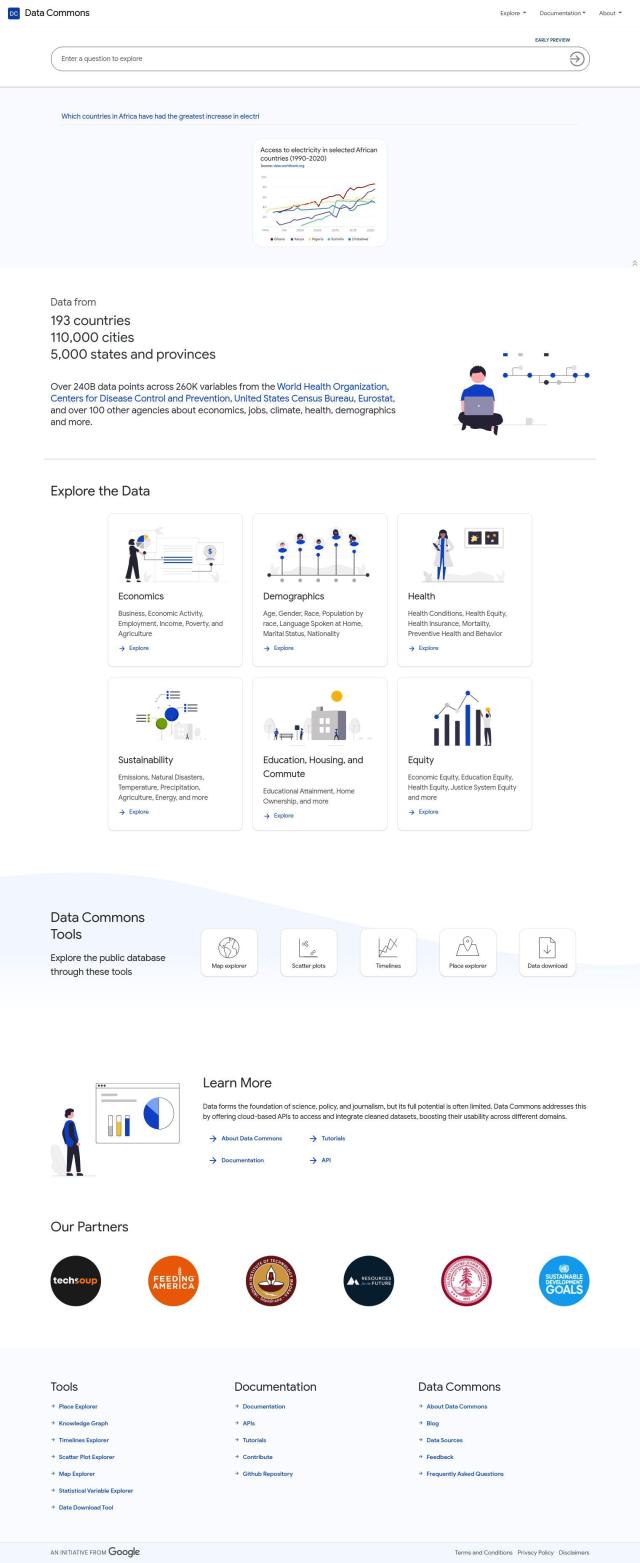
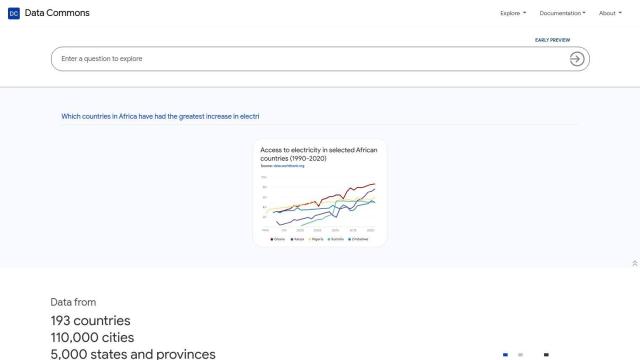
If you're looking for a data repository that offers cleaned and preprocessed data sets for scientific research and policy-making, Data Commons is a great option. This public repository collects data from more than 193 countries, 110,000 cities and 5,000 states and provinces, covering everything from economics and demographics to health, sustainability, education, housing and justice. With 240 billion data points and 260,000 variables, it offers cleaned and processed data through cloud-based programming interfaces. It's geared for researchers, policymakers and journalists, with tools like the Statistical Variable Explorer and Place Explorer.


Hugging Face
Another interesting option is Hugging Face, an open-source machine learning platform that offers a broad ecosystem for model collaboration, dataset exploration and application development. With more than 100,000 public datasets, it lets you host models, datasets and applications for free, and it's a good option for many scientific and research tasks. It also offers community support and access to the latest ML tools and developments, with pricing tiers for different needs.

Gretel Navigator
If you're interested in AI-generated and edited data, Gretel Navigator could be helpful. The system lets you create, edit and amplify tabular data with SQL or natural language prompts. It's good for training foundation models, fine-tuning large language models and creating evaluation datasets. With its real-time inference API, you can generate custom datasets on the fly, too, which can be useful for data augmentation and model testing.

Semantic Scholar
If you want to find and summarize lots of academic papers, Semantic Scholar is worth a look. This free AI-powered research service lets you search, read and organize scientific papers in a database of more than 219 million papers. It offers features like brief summaries, AI-powered research feeds and paper recommendations to help you follow the latest research in a particular field.