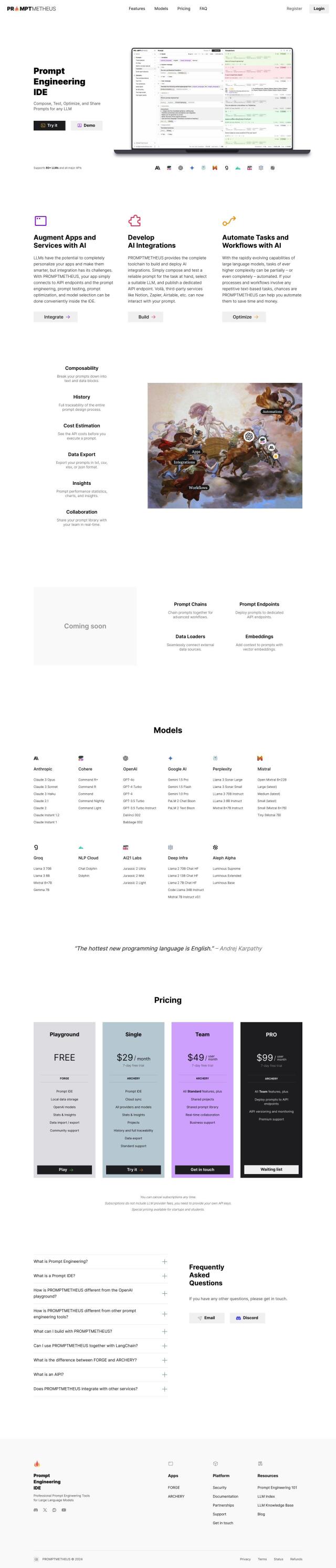
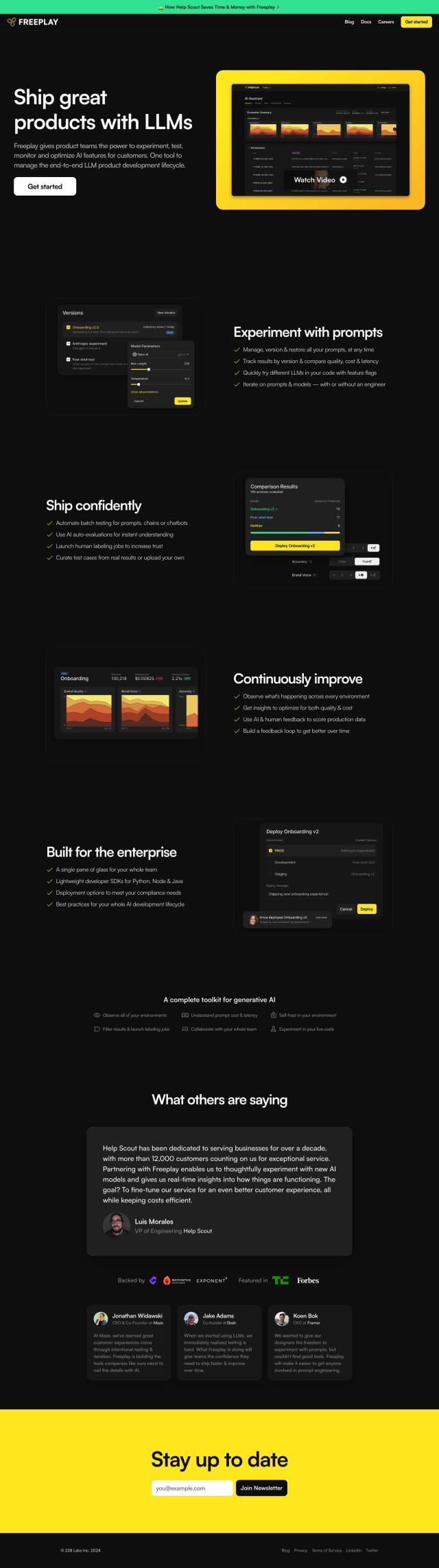
Question: I'm looking for a way to create and manage test suites for my language model, can you suggest a platform?

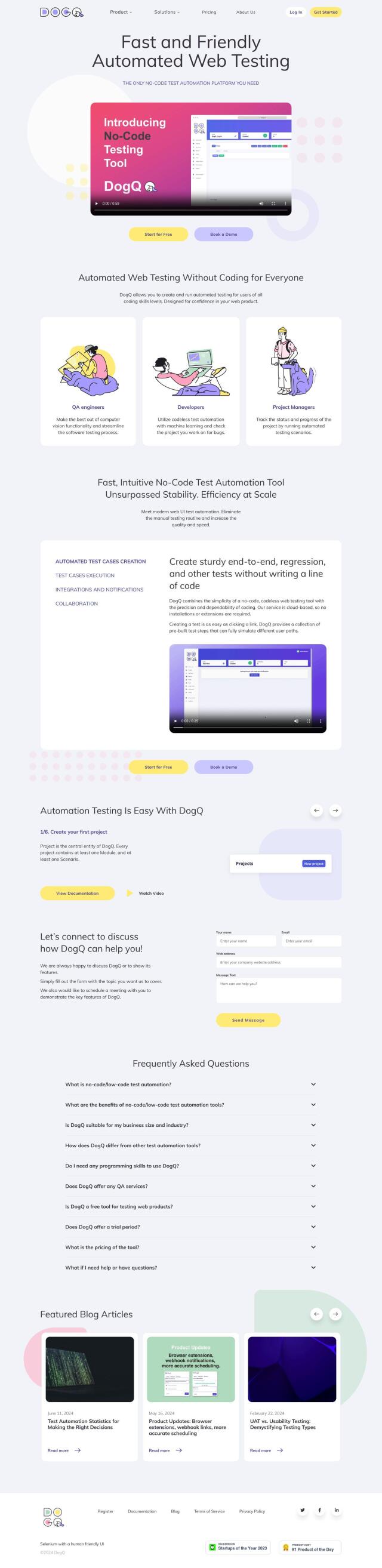
Langtail
For building and managing test suites for your language model, Langtail is a great option. It comes with a set of tools for debugging, testing and deploying LLM prompts, including running tests to ensure against unexpected behavior. Langtail has a no-code playground for writing and running prompts, tunable parameters and verbose logging. It's free for small businesses and solopreneurs, so it's a good option for those on a budget.

BenchLLM
Another powerful option is BenchLLM. The service lets developers build test suites and generate quality reports for LLM-based projects. It supports automated, interactive and custom evaluation methods and can be hooked up to APIs like OpenAI and Langchain. BenchLLM also automates evaluations, so you can easily add it to CI/CD pipelines and track performance regressions.

HoneyHive
HoneyHive is another option worth considering. The service offers a full suite of AI evaluation, testing and observability. That includes automated CI testing, production pipeline monitoring and debugging, with features like automated evaluators and human feedback collection. HoneyHive supports collaborative testing and deployment, so it's a good option for teams building GenAI applications.
Promptfoo
Finally, Promptfoo offers a command-line interface for evaluating LLM output quality. It's got a simple YAML-based configuration system and customizable evaluation metrics. Promptfoo supports multiple LLM providers and can be hooked up to existing processes, so it's a good option for developers who want to fine-tune model quality and monitor for regressions.