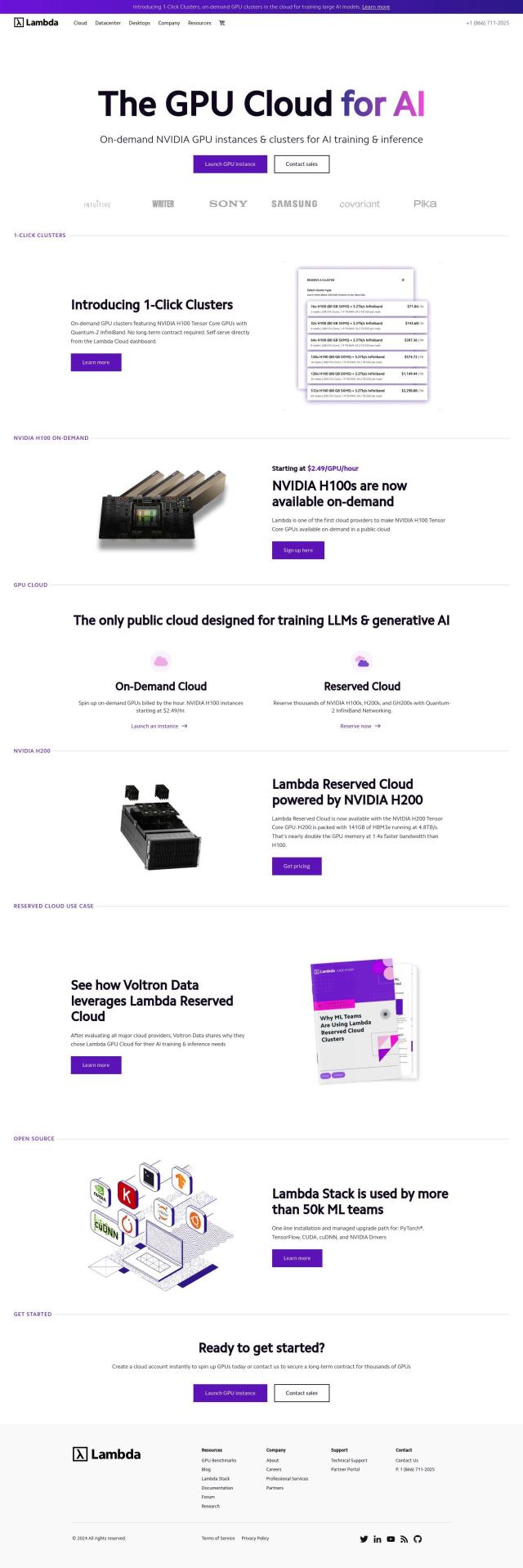
Question: Can you recommend a platform for training and fine-tuning large language models that's cost-effective and scalable?


Predibase
For a low-cost, scalable foundation for training and fine-tuning large language models, Predibase is a top contender. It lets developers fine-tune open-source LLMs for tasks like classification and code generation with state-of-the-art techniques like quantization. The service has a pay-as-you-go pricing model and comes with features like free serverless inference for up to 1 million tokens per day, enterprise-grade security, and support for a variety of models including Llama-2 and Mistral.
TrueFoundry
Another top contender is TrueFoundry, which speeds up ML and LLM work by accelerating deployment and cutting costs. It works on cloud and on-premise environments, has a unified manager for complex workflows, and integrates with existing stacks. TrueFoundry cuts production costs by 30-40% and shortens model deployment time, making it good for teams large or small.


Together
Together is another contender for fast and efficient generative AI model development and deployment. It includes new optimizations like Cocktail SGD and FlashAttention 2, and supports a variety of models for different AI tasks. Together offers scalable inference and collaborative tools for fine-tuning models, with big cost savings compared to other suppliers, up to 117x.


Tromero
For those who want a platform with multiple pricing options and an easy-to-use interface, Tromero is another top contender. It offers a three-step process for fine-tuning and deploying models, including a Tailor tool for quick model training and a Playground for model exploration. Tromero offers scalable and secure GPU Clusters, resulting in substantial cost savings and full data control for better security.