Question: I need a platform that provides robust testing and evaluation capabilities for AI model performance, along with analytics and insights for data quality and model optimization.

HoneyHive
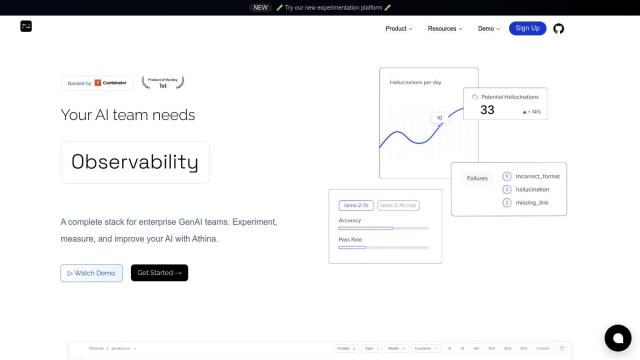
If you need a powerful platform to test AI model performance with a lot of testing and analytics, check out HoneyHive. This platform offers a unified environment for collaboration, testing and evaluation of GenAI applications. It includes automated CI testing, production pipeline monitoring, dataset curation and prompt management, with features like automated evaluators, human feedback collection and distributed tracing. With support for over 100 models and integration with popular GPU clouds, HoneyHive is great for teams that need powerful testing and optimization tools.


Humanloop
Another strong contender is Humanloop, which is geared for managing and optimizing the development of Large Language Models (LLMs). Humanloop's collaborative playground lets developers, product managers and domain experts iterate on AI features together, with tools for prompt management, evaluation and model optimization. It supports popular LLM providers and offers Python and TypeScript SDKs for easy integration, making it a good fit for product teams and developers who want to improve productivity and reliability.

Deepchecks
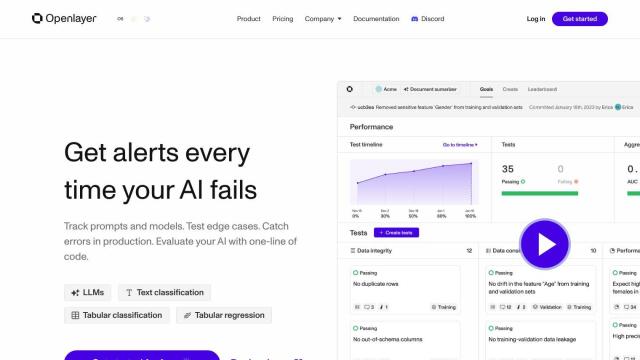
For those who want to ensure high-quality LLM applications, Deepchecks offers automated evaluation and problem detection. It includes a "Golden Set" approach for rich ground truth creation and has tools for debugging, version comparison and advanced testing. Deepchecks is designed to help developers and teams build reliable and high-quality AI applications from development to deployment.
Autoblocks
Last, Autoblocks offers an all-purpose AI evaluation platform that spans the full development lifecycle. It includes features like local testing, online evaluations, AI product analytics and prompt management, and integrates with popular tools like LangChain, LlamaIndex and Hugging Face. Autoblocks is good for collaborative development, where product managers and developers can rapidly iterate on AI products while meeting strict privacy and security requirements.