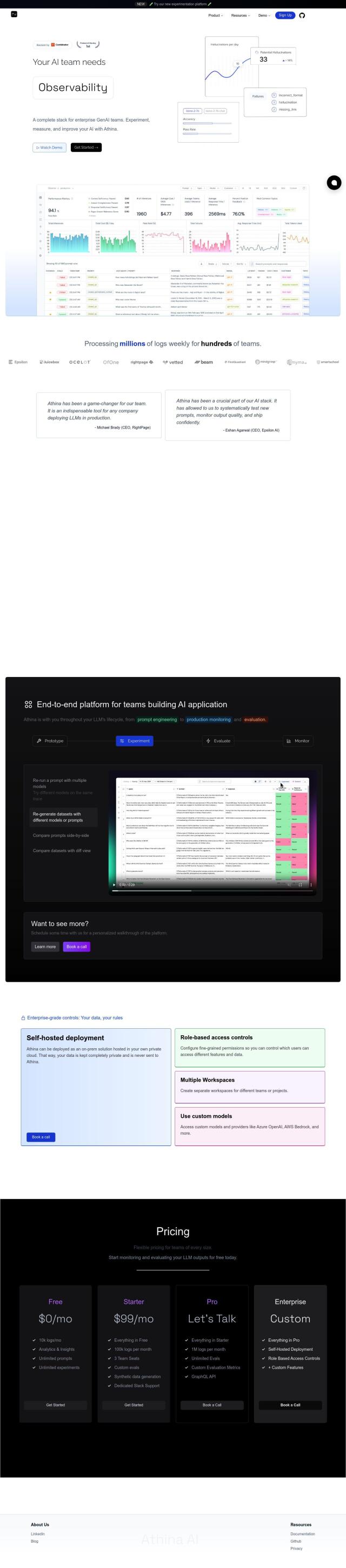
Question: Can you recommend a platform that provides a single environment for AI evaluation, testing, and observability, and supports features like automated evaluators and human feedback?

HoneyHive
If you're looking for a broad AI evaluation, testing and observability platform, HoneyHive stands out. It offers a unified environment for collaboration, testing and evaluation of applications, as well as tools for monitoring and debugging LLM failures in production. HoneyHive supports automated evaluators, human feedback collection, and distributed tracing with OpenTelemetry. It also offers features like dataset curation, labeling and versioning, making it a good option for managing and optimizing AI models.


Humanloop
Another good option is Humanloop, which is geared for managing and optimizing the development of Large Language Models. It offers a collaborative playground for developers, product managers and domain experts to develop and iterate on AI features. Humanloop offers tools for prompt management with version control and history tracking, and an evaluation and monitoring suite for debugging. It supports popular LLM providers and offers Python and TypeScript SDKs for easy integration, so it's good for both rapid prototyping and enterprise-scale deployments.


LastMile AI
LastMile AI is also worth a look, particularly if you need a platform that spans a broad range of generative AI applications. It includes features such as Auto-Eval for automated hallucination detection, RAG Debugger for performance improvement, and Consult AI Expert for expert assistance. LastMile AI's notebook-inspired environment, Workbooks, is good for prototyping and building apps with multiple AI models, making it easier to deploy production-ready generative AI applications.
Freeplay
For those who want an end-to-end lifecycle management tool, Freeplay is a good option for large language model product development. It offers prompt management and versioning, automated batch testing, AI auto-evaluations, and human labeling. Freeplay is designed to simplify development with a single pane of glass for teams, with lightweight developer SDKs for Python, Node, and Java, and deployment options for compliance needs.